-
 Life
Pretty_Nail - AI로 어떻게 손톱 물어뜯는걸 인식할까?
이전 글너 그게 맛있냐?다양한 방법들이 있다손톱 물어뜯는 걸 인식하는 AI는 내가 처음 떠올린걸까? 🧐구글에 검색해보면, 몇 가지 해외 블로그들을 찾아볼 수 있다. 해당 블로그에선 가장 쉽게 접근할 수 있는 방법론을 설명해 준다.간단하게 살펴 보자면,자신이 손톱을 물어뜯는 사진과 물어뜯지 않는 사진을 여러 장 찍어 모델을 학습시키는 것이다.Vision분야에서 가장 흔하게 볼 수 있는, 이미지 분류로 문제를 해결한것이다.이미지 분류의 주의점 → DataCentric의 중요성하지만, 위의 방법론으로는 데이터 관점에서 주의점이 보였다.우리가 개와 고양이를 분류하는 모델을 학습시킨다고 가정해 봤을 때,위처럼 인터넷에서 개와 고양이 사진 몇 장 가져와서 학습시키면 되겠지?라고 생각한다면 큰 오산이다.실제로는 아..
Life
Pretty_Nail - AI로 어떻게 손톱 물어뜯는걸 인식할까?
이전 글너 그게 맛있냐?다양한 방법들이 있다손톱 물어뜯는 걸 인식하는 AI는 내가 처음 떠올린걸까? 🧐구글에 검색해보면, 몇 가지 해외 블로그들을 찾아볼 수 있다. 해당 블로그에선 가장 쉽게 접근할 수 있는 방법론을 설명해 준다.간단하게 살펴 보자면,자신이 손톱을 물어뜯는 사진과 물어뜯지 않는 사진을 여러 장 찍어 모델을 학습시키는 것이다.Vision분야에서 가장 흔하게 볼 수 있는, 이미지 분류로 문제를 해결한것이다.이미지 분류의 주의점 → DataCentric의 중요성하지만, 위의 방법론으로는 데이터 관점에서 주의점이 보였다.우리가 개와 고양이를 분류하는 모델을 학습시킨다고 가정해 봤을 때,위처럼 인터넷에서 개와 고양이 사진 몇 장 가져와서 학습시키면 되겠지?라고 생각한다면 큰 오산이다.실제로는 아..
-
 Life
Pretty_Nail - 너 그게 맛있냐?
너 그게 맛있냐?초등학생 때 내 짝꿍이 한 소리다.손톱을 물어 뜯고있는 내 모습을 보고, 짝꿍이 한심하게 물어본 것이다..이게 맛있을 리가!.. 난 초등학생 때부터 손톱을 물어뜯는 버릇이 있었다.정확히 기억은 안 나는데, 궁금증에 한번 시작한 게20대 중반이 되어서 현재도 그러고 있다.생각보다 많은 사람들이 겪고 있다.어릴 적 무한도전을 보다가, 나랑 똑같은 손톱을 가진 하하를 발견했다.무한도전의 하하 VS 홍철에서 하하의 손톱이 짧은 것을 알고 홍철이 캔뚜껑 따기와 동전 줍기 대결을 신청한 것이다.(나빴다 홍철이!) 뿐만 아니다.당장에 구글과 YouTube에 손톱 물어뜯기 관련 검색을 해보면 수많은 포스팅과 영상이 뜬다. 심지어 교조증이라고, 이 버릇을 지칭하는 전문용어까지 등장할 정도로 많은 사람들이..
Life
Pretty_Nail - 너 그게 맛있냐?
너 그게 맛있냐?초등학생 때 내 짝꿍이 한 소리다.손톱을 물어 뜯고있는 내 모습을 보고, 짝꿍이 한심하게 물어본 것이다..이게 맛있을 리가!.. 난 초등학생 때부터 손톱을 물어뜯는 버릇이 있었다.정확히 기억은 안 나는데, 궁금증에 한번 시작한 게20대 중반이 되어서 현재도 그러고 있다.생각보다 많은 사람들이 겪고 있다.어릴 적 무한도전을 보다가, 나랑 똑같은 손톱을 가진 하하를 발견했다.무한도전의 하하 VS 홍철에서 하하의 손톱이 짧은 것을 알고 홍철이 캔뚜껑 따기와 동전 줍기 대결을 신청한 것이다.(나빴다 홍철이!) 뿐만 아니다.당장에 구글과 YouTube에 손톱 물어뜯기 관련 검색을 해보면 수많은 포스팅과 영상이 뜬다. 심지어 교조증이라고, 이 버릇을 지칭하는 전문용어까지 등장할 정도로 많은 사람들이..
-
 Docker
Udemy : Docker & Kubernetes 후기
이번에 글또 커뮤니티에서 좋은 기회로, 유데미의 Docker & Kubernetes 강의 쿠폰을 선물받을 수 있었습니다. 사실 이전에 도커를 공부해 보고자 두툼한 책을 샀었지만, 혼자서 많은 양을 공부하기란 쉽지 않더군요ㅜ 그런데 이번엔 글또에서 강의를 함께 공부할 스터디원을 만났습니다! 저는 함께하면 항상 끝까지 잘 완주하는 장점이 있는데, 역시 이번에도 함께 강의를 잘 완주할 수 있게 되었습니다. 그런 기념으로, 제가 들었던 강의의 솔직한 후기를 좋았던 점, 배웠던 점, 아쉬운 점, 앞으로 바라는 점에 대해서 후기를 하며, 자축을 하고자 합니다. 후기 Liked(좋았던 점) [추상적인 개념을 도식화로] 도커와 쿠버네티스는 개념 자체가 굉장히 추상적입니다. 이 강의에서 가장 좋았던 점은, 그 추상적인 ..
Docker
Udemy : Docker & Kubernetes 후기
이번에 글또 커뮤니티에서 좋은 기회로, 유데미의 Docker & Kubernetes 강의 쿠폰을 선물받을 수 있었습니다. 사실 이전에 도커를 공부해 보고자 두툼한 책을 샀었지만, 혼자서 많은 양을 공부하기란 쉽지 않더군요ㅜ 그런데 이번엔 글또에서 강의를 함께 공부할 스터디원을 만났습니다! 저는 함께하면 항상 끝까지 잘 완주하는 장점이 있는데, 역시 이번에도 함께 강의를 잘 완주할 수 있게 되었습니다. 그런 기념으로, 제가 들었던 강의의 솔직한 후기를 좋았던 점, 배웠던 점, 아쉬운 점, 앞으로 바라는 점에 대해서 후기를 하며, 자축을 하고자 합니다. 후기 Liked(좋았던 점) [추상적인 개념을 도식화로] 도커와 쿠버네티스는 개념 자체가 굉장히 추상적입니다. 이 강의에서 가장 좋았던 점은, 그 추상적인 ..
-
 Generative AI
Rag : 나만의 LLM을 만들자
무엇이든 잘 대답하는 LLM의 한계 ChatGPT가 놀랍다는 건 이제 너무 지루한 말이 되어 버렸습니다. 이미 이 같은 대규모 언어 모델(Large Language Model, LLM)들을 많은 이들이 자신의 업무에 적용해 생산성을 크게 향상시키고 있죠. 무엇이든 잘 답변해 내는 걸 보면, 이제 AI가 아니라 마치 요술램프 지니 같기도 합니다. 그러나, 이러한 LLM의 범용성에도 불구하고, 특정 도메인에 대한 세밀한 정보를 원하는 데는 한계가 있습니다. 예를 들어 특정 지역의 특정 은행 지점의 운영 시간과 같은 질문에 대해 LLM은 그 은행의 구체적인 정보를 알지 못하여, 가장 일반적인 응답을 제공할 가능성이 높은 것처럼 말이죠. 이는 LLM의 큰 한계점 중 하나인 할루시네이션 현상이기도 하죠. 이는 많..
Generative AI
Rag : 나만의 LLM을 만들자
무엇이든 잘 대답하는 LLM의 한계 ChatGPT가 놀랍다는 건 이제 너무 지루한 말이 되어 버렸습니다. 이미 이 같은 대규모 언어 모델(Large Language Model, LLM)들을 많은 이들이 자신의 업무에 적용해 생산성을 크게 향상시키고 있죠. 무엇이든 잘 답변해 내는 걸 보면, 이제 AI가 아니라 마치 요술램프 지니 같기도 합니다. 그러나, 이러한 LLM의 범용성에도 불구하고, 특정 도메인에 대한 세밀한 정보를 원하는 데는 한계가 있습니다. 예를 들어 특정 지역의 특정 은행 지점의 운영 시간과 같은 질문에 대해 LLM은 그 은행의 구체적인 정보를 알지 못하여, 가장 일반적인 응답을 제공할 가능성이 높은 것처럼 말이죠. 이는 LLM의 큰 한계점 중 하나인 할루시네이션 현상이기도 하죠. 이는 많..
-
 Life
내가 AI를 즐겁게 시작했던 방법, 해커톤
AI를 공부한다는 것은 방대한 항해를 시작하는 것과 같아요. 너무나 많은 분야들이 있고, 각 분야마다 매일 새로운 기술들이 등장하죠. AI에 이제 막 관심 가진 학생이라면, 어디서부터 시작해야 할지 막막할 수 있습니다. 대학원, 부트캠프 등 AI를 공부하기 위한 좋은 수단들이 있지만, 해커톤도 정말 좋은 공부의 수단이 될 수 있다고 생각합니다. 우리가 AI 기술을 공부하는 이유를 잘 생각해 보면, 결국 특정 문제를 AI로 해결하려는 것에 있습니다. 해커톤은 이를 연습하기 가장 좋은 수단이라 생각해요. 다양한 기업이나 단체에서 내놓은 문제들을 참가자들이 서로 다른 방법으로 솔루션을 제시하고, 그중에서 가장 적합한 솔루션을 선정하는 과정에서 문제 해결력을 기를 수 있거든요. 학생이라는 입장에서 조금이나마 현..
Life
내가 AI를 즐겁게 시작했던 방법, 해커톤
AI를 공부한다는 것은 방대한 항해를 시작하는 것과 같아요. 너무나 많은 분야들이 있고, 각 분야마다 매일 새로운 기술들이 등장하죠. AI에 이제 막 관심 가진 학생이라면, 어디서부터 시작해야 할지 막막할 수 있습니다. 대학원, 부트캠프 등 AI를 공부하기 위한 좋은 수단들이 있지만, 해커톤도 정말 좋은 공부의 수단이 될 수 있다고 생각합니다. 우리가 AI 기술을 공부하는 이유를 잘 생각해 보면, 결국 특정 문제를 AI로 해결하려는 것에 있습니다. 해커톤은 이를 연습하기 가장 좋은 수단이라 생각해요. 다양한 기업이나 단체에서 내놓은 문제들을 참가자들이 서로 다른 방법으로 솔루션을 제시하고, 그중에서 가장 적합한 솔루션을 선정하는 과정에서 문제 해결력을 기를 수 있거든요. 학생이라는 입장에서 조금이나마 현..
-
 Generative AI
GPTs, 나의 과거 프로젝트를 구현하다.
또 다른 패러다임의 전환, GPTs 패러다임 : 한 시대의 보편적 사고의 틀이나 인식의 체계 AI계에서, 2023년은 ChatGPT의 해였다고 해도 과언이 아닙니다. 개발자는 물론 디자인과 기획, 의료, 법, 등 분야를 막론하고 ChatGPT의 기술을 도입하려 하고 있죠. 아마 ChatGPT에 영향을 받지 않은 분야는 단 하나도 남지 않았을 것입니다. 이러한 전환을 가속화할 새로운 녀석이 나타났습니다. 바로 GPTs입니다. 이제 자신만의 ChatGPT를 아주 손쉽게 만들어낼 수 있게 되었습니다. 이모티콘 생성기, 법률 비서, 의료 비서, 논문 요약기 등 ChatGPT를 베이스로 한 다양한 서비스들을 아주 쉽게 만들 수 있게 되었죠. 더군다나 이렇게 만든 GPTs를 세상에 공유할 수 있는 플랫폼도 탄생했습..
Generative AI
GPTs, 나의 과거 프로젝트를 구현하다.
또 다른 패러다임의 전환, GPTs 패러다임 : 한 시대의 보편적 사고의 틀이나 인식의 체계 AI계에서, 2023년은 ChatGPT의 해였다고 해도 과언이 아닙니다. 개발자는 물론 디자인과 기획, 의료, 법, 등 분야를 막론하고 ChatGPT의 기술을 도입하려 하고 있죠. 아마 ChatGPT에 영향을 받지 않은 분야는 단 하나도 남지 않았을 것입니다. 이러한 전환을 가속화할 새로운 녀석이 나타났습니다. 바로 GPTs입니다. 이제 자신만의 ChatGPT를 아주 손쉽게 만들어낼 수 있게 되었습니다. 이모티콘 생성기, 법률 비서, 의료 비서, 논문 요약기 등 ChatGPT를 베이스로 한 다양한 서비스들을 아주 쉽게 만들 수 있게 되었죠. 더군다나 이렇게 만든 GPTs를 세상에 공유할 수 있는 플랫폼도 탄생했습..
-
 Generative AI
[StableDiffusion] Virtual Try On : 원하는 옷을 입혀보자
어디에나 필요한 Virtual Try On 최근 친구가 취업에 성공했습니다. 사원증에 필요한 사진을 회사에 제출해야 했는데, 이것저것 바쁜 일이 많았던 친구는 일반 증명사진에 정장을 합성하기로 하죠. 당시 저는 StableDiffusion을 활용해, 옷을 변경하는 로직을 구상 중이었습니다. 마침 테스트로 활용할 실험군이 나타난 것이죠. 포토샵을 다룰 줄 몰랐지만, 선뜻해준다고 나섰습니다. 그 결과, 아래와 같이 정장을 입혀주게 되었습니다. 꽤나 마음에 들어 하던 친구는 이를 사원증으로 사용하게 되었죠. 서론이 조금 길었습니다. 위처럼, 디지털 환경에서 옷이나 액세서리를 가상으로 착용해 보는 기술을 "Virtual Try-On"이라 합니다. 꽤 많은 니즈가 있고, 이를 위한 많은 연구가 있어 왔죠. 이번 ..
Generative AI
[StableDiffusion] Virtual Try On : 원하는 옷을 입혀보자
어디에나 필요한 Virtual Try On 최근 친구가 취업에 성공했습니다. 사원증에 필요한 사진을 회사에 제출해야 했는데, 이것저것 바쁜 일이 많았던 친구는 일반 증명사진에 정장을 합성하기로 하죠. 당시 저는 StableDiffusion을 활용해, 옷을 변경하는 로직을 구상 중이었습니다. 마침 테스트로 활용할 실험군이 나타난 것이죠. 포토샵을 다룰 줄 몰랐지만, 선뜻해준다고 나섰습니다. 그 결과, 아래와 같이 정장을 입혀주게 되었습니다. 꽤나 마음에 들어 하던 친구는 이를 사원증으로 사용하게 되었죠. 서론이 조금 길었습니다. 위처럼, 디지털 환경에서 옷이나 액세서리를 가상으로 착용해 보는 기술을 "Virtual Try-On"이라 합니다. 꽤 많은 니즈가 있고, 이를 위한 많은 연구가 있어 왔죠. 이번 ..
-
 Life
글또 회고와 시작
글또 8기가 막을 내렸습니다. 그리고 9기가 시작되었어요. 지난 글쓰기 활동을 회고해 보며, 앞으로의 방향을 가져보려 합니다. 글또를 하며 느낀 점 [너무 완벽한 글을 쓰려다 골병들지 말자!] 꽤 많은 사람들이 완벽한 글을 쓰려다 지쳐버리는 것을 알게 되었습니다. 제가 그랬었기 때문에, 그 어려움이 너무나 공감이 됩니다. 생각을 글로 표현하는 것 자체가 힘든 활동인 데다, 기술 내용을 다루는 글이라면 어려움은 배가 되는 것 같아요. 처음부터 글을 너무 진지하게 대하진 않으려 해요. 명심해야 할 부분은, 제가 책을 집필하는 작가가 아니라는 점입니다. 교수님께 평가받을 과제를 하는 것도 아니고요. 즉, 작은 재미를 가질 수 있을 정도로, 조금 더 가볍게 글을 대하려 합니다. 그래야 지속적으로 글쓰기를 접할 ..
Life
글또 회고와 시작
글또 8기가 막을 내렸습니다. 그리고 9기가 시작되었어요. 지난 글쓰기 활동을 회고해 보며, 앞으로의 방향을 가져보려 합니다. 글또를 하며 느낀 점 [너무 완벽한 글을 쓰려다 골병들지 말자!] 꽤 많은 사람들이 완벽한 글을 쓰려다 지쳐버리는 것을 알게 되었습니다. 제가 그랬었기 때문에, 그 어려움이 너무나 공감이 됩니다. 생각을 글로 표현하는 것 자체가 힘든 활동인 데다, 기술 내용을 다루는 글이라면 어려움은 배가 되는 것 같아요. 처음부터 글을 너무 진지하게 대하진 않으려 해요. 명심해야 할 부분은, 제가 책을 집필하는 작가가 아니라는 점입니다. 교수님께 평가받을 과제를 하는 것도 아니고요. 즉, 작은 재미를 가질 수 있을 정도로, 조금 더 가볍게 글을 대하려 합니다. 그래야 지속적으로 글쓰기를 접할 ..
-
 Medical AI
[Torchio]-3D Segmentation
Torchio? Torchio는 Pytorch를 기반으로 구현되어 있으며, 3D Segmentation 특히 의료 분야의 데이터를 분석하기 용이한 오픈소스 라이브러리입니다. 이번 포스팅에서는 Torchio 내에서 3D 데이터를 로드하고 모델에 입력해 주는 과정을 담당하는 DataStructures, 다양한 기법으로 데이터를 전처리 및 증강 해주는 Transform, 큰 용량의 3D 데이터를 효과적으로 학습하게 해주는 Patch-Based Pipeline 부분을 소개해 드리고자 합니다. torchio를 활용해 3D segmentation을 직접 진행할 필요가 있으시다면, 아래 글을 읽고 torchio에서 제공해 주는 공식 튜토리얼을 학습해 보는 걸 추천드립니다.🤠 (Torchio 공식 tutorial : ..
Medical AI
[Torchio]-3D Segmentation
Torchio? Torchio는 Pytorch를 기반으로 구현되어 있으며, 3D Segmentation 특히 의료 분야의 데이터를 분석하기 용이한 오픈소스 라이브러리입니다. 이번 포스팅에서는 Torchio 내에서 3D 데이터를 로드하고 모델에 입력해 주는 과정을 담당하는 DataStructures, 다양한 기법으로 데이터를 전처리 및 증강 해주는 Transform, 큰 용량의 3D 데이터를 효과적으로 학습하게 해주는 Patch-Based Pipeline 부분을 소개해 드리고자 합니다. torchio를 활용해 3D segmentation을 직접 진행할 필요가 있으시다면, 아래 글을 읽고 torchio에서 제공해 주는 공식 튜토리얼을 학습해 보는 걸 추천드립니다.🤠 (Torchio 공식 tutorial : ..
-
 Generative AI
[Stable Diffusion] ControlNet이란? ControlNet의 종류
이미지를 생성해 주는 인공지능이 처음 나왔을 때, 그 퀄리티에 놀란적이 있습니다. 2022년 4월, DALL·E 2가 세상에 공개되었을 땐, 이젠 웬만한 사람이 흉내 낼 수 없는 퀄리티를 보이기도 했습니다. 퀄리티면에서는 사람이 AI를 이기기란 어려운 일이 되어버렸습니다. 하지만 이런 발전에도 불구하고, 사용자의 의도를 정확히 반영하는 것은 여전히 어려운 문제로 남아있습니다. 사용자는 AI에게 프롬프트를 제공할 수 있을 뿐, 그 이후에는 AI가 확률적 알고리즘에 따라 이미지를 생성합니다. 때문에, 매번 다른 이미지를 생성하게 되고, 정확히 사용자가 원하는 그림을 얻기까지는 수많은 노력과 시간이 필요합니다. 한 가지 예시를 보겠습니다. 아래는 Stable Diffusion을 활용해 테니스를 치는 아이언맨을..
Generative AI
[Stable Diffusion] ControlNet이란? ControlNet의 종류
이미지를 생성해 주는 인공지능이 처음 나왔을 때, 그 퀄리티에 놀란적이 있습니다. 2022년 4월, DALL·E 2가 세상에 공개되었을 땐, 이젠 웬만한 사람이 흉내 낼 수 없는 퀄리티를 보이기도 했습니다. 퀄리티면에서는 사람이 AI를 이기기란 어려운 일이 되어버렸습니다. 하지만 이런 발전에도 불구하고, 사용자의 의도를 정확히 반영하는 것은 여전히 어려운 문제로 남아있습니다. 사용자는 AI에게 프롬프트를 제공할 수 있을 뿐, 그 이후에는 AI가 확률적 알고리즘에 따라 이미지를 생성합니다. 때문에, 매번 다른 이미지를 생성하게 되고, 정확히 사용자가 원하는 그림을 얻기까지는 수많은 노력과 시간이 필요합니다. 한 가지 예시를 보겠습니다. 아래는 Stable Diffusion을 활용해 테니스를 치는 아이언맨을..
-
 Server
[Serverless] Serverless의 모든것
컴퓨터의 역사를 되돌아보면, 여러 차례에 걸쳐 큰 "패러다임의 전환"들이 있었습니다. 처음에는 단순한 계산을 수행하는 컴퓨터에 사람들이 경이로워했던 시절이 있었습니다. 그러나 가상 머신의 등장으로 물리적인 하드웨어의 제약에서 벗어나, 더 유연하고 효율적인 컴퓨팅 환경을 구성할 수 있게 되었습니다. 그리고는 컨테이너 기술이 나타나, 서버 환경과 그 설정을 덜 복잡하게 만들어, 개발자가 문제 해결의 핵심에만 집중할 수 있게 해 주었습니다. 이러한 패러다임의 전환들로 인해 컴퓨팅의 많은 생태계가 발전되어 왔죠. 이번에 소개할 서버리스 또한 이러한 패러다임의 새로운 전환점을 차지하고 있습니다. Serverless란? 서버리스(Serverless)는 클라우드 서비스의 한 종류로, 개발자가 서버의 관리에 신경 쓰지..
Server
[Serverless] Serverless의 모든것
컴퓨터의 역사를 되돌아보면, 여러 차례에 걸쳐 큰 "패러다임의 전환"들이 있었습니다. 처음에는 단순한 계산을 수행하는 컴퓨터에 사람들이 경이로워했던 시절이 있었습니다. 그러나 가상 머신의 등장으로 물리적인 하드웨어의 제약에서 벗어나, 더 유연하고 효율적인 컴퓨팅 환경을 구성할 수 있게 되었습니다. 그리고는 컨테이너 기술이 나타나, 서버 환경과 그 설정을 덜 복잡하게 만들어, 개발자가 문제 해결의 핵심에만 집중할 수 있게 해 주었습니다. 이러한 패러다임의 전환들로 인해 컴퓨팅의 많은 생태계가 발전되어 왔죠. 이번에 소개할 서버리스 또한 이러한 패러다임의 새로운 전환점을 차지하고 있습니다. Serverless란? 서버리스(Serverless)는 클라우드 서비스의 한 종류로, 개발자가 서버의 관리에 신경 쓰지..
-
 Docker
딥러닝 서비스 컨테이너화 #1
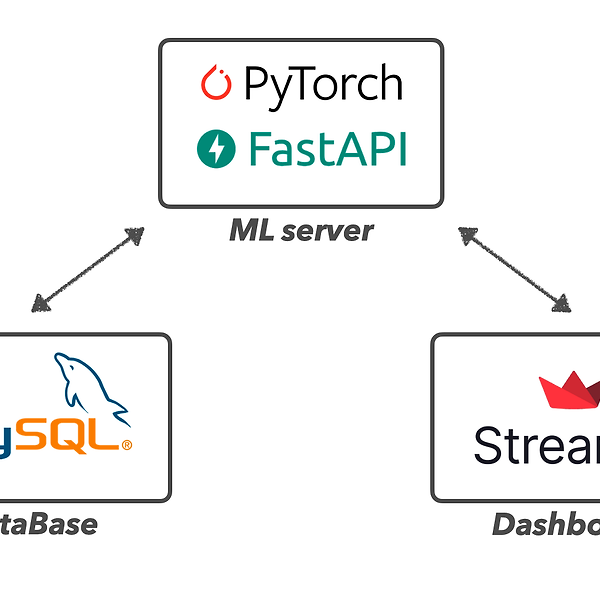
모델 서빙이란 AI 서비스 관점에서, 모델을 잘 학습시키는 것 외에 해야 할 단계가 하나 더 있습니다. 바로 모델을 서빙하는 단계입니다. 잘 학습시킨 모델을 유저들이 사용할 수 있도록 실제 애플리케이션에 녹여내는 과정이라 보면 되겠습니다. 이 서빙 단계에서는 고려해 줘야 할게 한두 가지가 아닙니다. 유저들의 데이터는 어디에 보관할지, 모델 추론 시간을 실시간성으로 확보할 수 있을지, 유저들이 한꺼번에 몰릴 때는 어떻게 확장할지 등 엔지니어링 관점으로 고려해야 할게 수도 없이 많습니다. 그러한 과정을 잘 나타내주는 테크블로그 하나를 소개하고자 합니다. 이번 포스팅에서는 서빙단계에서 가장 기본이 되는 "컨테이너화"를 중점으로, 간단한 딥러닝 서비스를 컨테이너화하는 과정을 기록하고자 합니다. 딥러닝 서비스의 ..
Docker
딥러닝 서비스 컨테이너화 #1
모델 서빙이란 AI 서비스 관점에서, 모델을 잘 학습시키는 것 외에 해야 할 단계가 하나 더 있습니다. 바로 모델을 서빙하는 단계입니다. 잘 학습시킨 모델을 유저들이 사용할 수 있도록 실제 애플리케이션에 녹여내는 과정이라 보면 되겠습니다. 이 서빙 단계에서는 고려해 줘야 할게 한두 가지가 아닙니다. 유저들의 데이터는 어디에 보관할지, 모델 추론 시간을 실시간성으로 확보할 수 있을지, 유저들이 한꺼번에 몰릴 때는 어떻게 확장할지 등 엔지니어링 관점으로 고려해야 할게 수도 없이 많습니다. 그러한 과정을 잘 나타내주는 테크블로그 하나를 소개하고자 합니다. 이번 포스팅에서는 서빙단계에서 가장 기본이 되는 "컨테이너화"를 중점으로, 간단한 딥러닝 서비스를 컨테이너화하는 과정을 기록하고자 합니다. 딥러닝 서비스의 ..
-
 Docker
Docker Network : 호스트와 컨테이너를 위한 네트워크를 구성해보자
컨테이너가 실행될 때, 특정 내부 IP가 할당됩니다. 이때 내부 IP만으로는 외부와의 통신이 불가능하죠. 우리가 컨테이너를 활용하다 보면, 컨테이너와 컨테이너, 컨테이너와 호스트 등 서로 통신이 가능해야 할 순간이 필수일 겁니다. 이를 위해, 도커의 네트워크 구조를 살펴보고, 이러한 구조 아래에서 다양한 네트워크를 구성해 보겠습니다. 도커 네트워크의 구조 도커의 기본적인 네트워크 구조는 아래와 같습니다. 우리가 확인해 봐야 할 요소는 크게 호스트의 eth0, 기본 브리지인 docker0, 컨테이너의 가상 네트워크 인터페이스인 veth 이 3가지입니다. 각각의 요소를 살펴보겠습니다. eth0 호스트의 eth0은, 실제 우리가 외부와 연결할 때 사용하는 IP가 할당된 호스트 네트워크 인터페이스입니다. doc..
Docker
Docker Network : 호스트와 컨테이너를 위한 네트워크를 구성해보자
컨테이너가 실행될 때, 특정 내부 IP가 할당됩니다. 이때 내부 IP만으로는 외부와의 통신이 불가능하죠. 우리가 컨테이너를 활용하다 보면, 컨테이너와 컨테이너, 컨테이너와 호스트 등 서로 통신이 가능해야 할 순간이 필수일 겁니다. 이를 위해, 도커의 네트워크 구조를 살펴보고, 이러한 구조 아래에서 다양한 네트워크를 구성해 보겠습니다. 도커 네트워크의 구조 도커의 기본적인 네트워크 구조는 아래와 같습니다. 우리가 확인해 봐야 할 요소는 크게 호스트의 eth0, 기본 브리지인 docker0, 컨테이너의 가상 네트워크 인터페이스인 veth 이 3가지입니다. 각각의 요소를 살펴보겠습니다. eth0 호스트의 eth0은, 실제 우리가 외부와 연결할 때 사용하는 IP가 할당된 호스트 네트워크 인터페이스입니다. doc..
-
 Docker
Docker Volume : 컨테이너의 데이터를 영속적으로 보관해 보자
Docker Volume 도커 이미지를 컨테이너로 실행하게 되면, 컨테이너는 아래 보이는 그림처럼 이미지레이어 위에 컨테이너레이어가 구성되었는 구조를 가집니다. 이때 이미지 레이어는 읽기전용(read only)이기에, 컨테이너로 무슨 작업을 하던 이 이미지 레이어는 어떠한 영향도 받지 않습니다. 반면, 컨테이너 레이어는 읽고 쓸수 있는 구조이기에(read & write), 컨테이너 내에서 생성되는 데이터는 해당 컨테이너 레이어에 저장되게 되죠. 리눅스의 union file system 기술이 위의 레이어들을 하나의 시스템처럼 동작할 수 있도록 해줍니다. 하지만, 여기에는 큰 위험성이 존재합니다. 해당 컨테이너를 삭제시키면, 컨테이너 레이어도 동시에 삭제되기 때문에 저장되어 있던 소중한 데이터를 잃을 수 ..
Docker
Docker Volume : 컨테이너의 데이터를 영속적으로 보관해 보자
Docker Volume 도커 이미지를 컨테이너로 실행하게 되면, 컨테이너는 아래 보이는 그림처럼 이미지레이어 위에 컨테이너레이어가 구성되었는 구조를 가집니다. 이때 이미지 레이어는 읽기전용(read only)이기에, 컨테이너로 무슨 작업을 하던 이 이미지 레이어는 어떠한 영향도 받지 않습니다. 반면, 컨테이너 레이어는 읽고 쓸수 있는 구조이기에(read & write), 컨테이너 내에서 생성되는 데이터는 해당 컨테이너 레이어에 저장되게 되죠. 리눅스의 union file system 기술이 위의 레이어들을 하나의 시스템처럼 동작할 수 있도록 해줍니다. 하지만, 여기에는 큰 위험성이 존재합니다. 해당 컨테이너를 삭제시키면, 컨테이너 레이어도 동시에 삭제되기 때문에 저장되어 있던 소중한 데이터를 잃을 수 ..
-
 Docker
Dockerfile & Commit : 나만의 애플리케이션을 Docker Image로 만들어 보자
나만의 Docker Image를 만들어보자 도커 허브에서 우리가 필요로 하는 이미지를 docker pull 명령어를 통해 마음껏 가져올 수 있습니다. 하지만, 도커 허브에 존재하지 않는, 우리만의 프로젝트를 이미지로 만들어 공유해야 할 순간이 있습니다. 이러한 순간을 대비해, 직접 커스텀 이미지를 만드는 방법을 알아보고자 합니다. 나만의 커스텀 이미지를 만들기 위해선 크게 Dockerfile을 이용하는 방법과, Commit 명령어를 이용하는 방법 2가지로 나눠볼 수 있습니다. 해당 포스팅에서 얻어갈 수 있는 정보는 아래와 같습니다. Commit을 통해 이미지 생성하기 Dockerfile을 통해 이미지 생성하기 Commit을 통해 이미지 생성하기 commit 명령어는 현재 작업중인 컨테이너를 이미지로 변환..
Docker
Dockerfile & Commit : 나만의 애플리케이션을 Docker Image로 만들어 보자
나만의 Docker Image를 만들어보자 도커 허브에서 우리가 필요로 하는 이미지를 docker pull 명령어를 통해 마음껏 가져올 수 있습니다. 하지만, 도커 허브에 존재하지 않는, 우리만의 프로젝트를 이미지로 만들어 공유해야 할 순간이 있습니다. 이러한 순간을 대비해, 직접 커스텀 이미지를 만드는 방법을 알아보고자 합니다. 나만의 커스텀 이미지를 만들기 위해선 크게 Dockerfile을 이용하는 방법과, Commit 명령어를 이용하는 방법 2가지로 나눠볼 수 있습니다. 해당 포스팅에서 얻어갈 수 있는 정보는 아래와 같습니다. Commit을 통해 이미지 생성하기 Dockerfile을 통해 이미지 생성하기 Commit을 통해 이미지 생성하기 commit 명령어는 현재 작업중인 컨테이너를 이미지로 변환..
-
 Docker
Docker의 구성 요소 : 이미지, 컨테이너, 레이어
도커의 필요성 도커를 처음 공부했을 때는 “어렵기만 하다”생각했습니다. 내가 왜 이 어려운 내용을 배우고 있는 건지, 그 어떤 목적성과 필요성이 없었기 때문이죠. 이처럼, 무작정 도커를 공부하려 하면 이해 안 가는 게 투성이 일 것입니다. 어렵기도 하고요. 하지만, 도커가 필요한 순간을 몇 번 마주치고 그 맥락을 인지하게 되면, 도커만큼 재밌고 또 잘 다루고 싶은 툴은 없을 거라 생각합니다. (깃도 비슷한 맥락이겠네요) 그러한 관점에서, 개인적으로 도커의 필요성을 느낀 순간을 공유하고자 합니다. 작년, 딥러닝 관련 외주 프로젝트를 진행할 당시였습니다. 마감 기한을 2일 남겨놓고 필요한 모든 코드와 테스트를 완료해 놓았습니다. 최종 데모를 위해 다른 컴퓨터에 실행만 시키면 되는 상황이었기에 매우 여유로웠습..
Docker
Docker의 구성 요소 : 이미지, 컨테이너, 레이어
도커의 필요성 도커를 처음 공부했을 때는 “어렵기만 하다”생각했습니다. 내가 왜 이 어려운 내용을 배우고 있는 건지, 그 어떤 목적성과 필요성이 없었기 때문이죠. 이처럼, 무작정 도커를 공부하려 하면 이해 안 가는 게 투성이 일 것입니다. 어렵기도 하고요. 하지만, 도커가 필요한 순간을 몇 번 마주치고 그 맥락을 인지하게 되면, 도커만큼 재밌고 또 잘 다루고 싶은 툴은 없을 거라 생각합니다. (깃도 비슷한 맥락이겠네요) 그러한 관점에서, 개인적으로 도커의 필요성을 느낀 순간을 공유하고자 합니다. 작년, 딥러닝 관련 외주 프로젝트를 진행할 당시였습니다. 마감 기한을 2일 남겨놓고 필요한 모든 코드와 테스트를 완료해 놓았습니다. 최종 데모를 위해 다른 컴퓨터에 실행만 시키면 되는 상황이었기에 매우 여유로웠습..
-
 Generative AI
AutoEncoder
생성 모델의 한 축을 담당하는 Variational Autoencoder를 이해하기 위해서는, Autoencoder를 그냥 지나칠 수 없습니다. 이번 글에서는 Autoencoder에 대해 이해해 보는 시간을 가져보겠습니다. Autoencoder Autoencoder는 위의 그림과 같은 구조를 가지고 있으며 Encoder, Latent Vector, Decoder 이 3가지의 구성으로 이루어져 있습니다. 해당 모델의 가장 큰 목표는 데이터를 잘 압축하고자 하는 것입니다. 이 3가지의 구성 요소들이 어떻게 데이터를 잘 압축할 수 있도록 해주는지 하나하나씩 살펴보도록 하겠습니다. Autoencoder의 목표는 데이터를 잘 압축하는데에 있다. Encoder Autoencoder에서 Encoder의 역할은 입력된..
Generative AI
AutoEncoder
생성 모델의 한 축을 담당하는 Variational Autoencoder를 이해하기 위해서는, Autoencoder를 그냥 지나칠 수 없습니다. 이번 글에서는 Autoencoder에 대해 이해해 보는 시간을 가져보겠습니다. Autoencoder Autoencoder는 위의 그림과 같은 구조를 가지고 있으며 Encoder, Latent Vector, Decoder 이 3가지의 구성으로 이루어져 있습니다. 해당 모델의 가장 큰 목표는 데이터를 잘 압축하고자 하는 것입니다. 이 3가지의 구성 요소들이 어떻게 데이터를 잘 압축할 수 있도록 해주는지 하나하나씩 살펴보도록 하겠습니다. Autoencoder의 목표는 데이터를 잘 압축하는데에 있다. Encoder Autoencoder에서 Encoder의 역할은 입력된..
-
 Generative AI
확률 관점으로 바라보는 머신러닝
Variational AutoEncoder를 이해하기 위해서는 기존의 머신러닝 관점을 확률론적 관점으로 바라볼 수 있어야 합니다. 해당 글은 이활석님의 오토인코더의 모든것이라는 강연을 보고 정리한 느낌이 되겠습니다. 이번 포스팅에서는 아래의 문구를 이해하는데 초점을 맞추며 내용을 이어갈 계획입니다. 딥러닝 모델을 학습시킨 다는 것은 Maximum Likelihood Estimation 하는 것과 같은 말이다. 기존의 머신러닝 학습 과정 우리가 일반적으로 머신러닝을 처음 공부할 때, 아래와 같은 메커니즘으로 모델이 동작한다는것을 배웁니다. 학습데이터 x를 모델에 입력한다. 입력값 x가 모델 내의 파라미터(Weight and Bias)를 거쳐가며 예측값인 y_pred를 출력해 낸다. 이렇게 얻은 예측값 y_..
Generative AI
확률 관점으로 바라보는 머신러닝
Variational AutoEncoder를 이해하기 위해서는 기존의 머신러닝 관점을 확률론적 관점으로 바라볼 수 있어야 합니다. 해당 글은 이활석님의 오토인코더의 모든것이라는 강연을 보고 정리한 느낌이 되겠습니다. 이번 포스팅에서는 아래의 문구를 이해하는데 초점을 맞추며 내용을 이어갈 계획입니다. 딥러닝 모델을 학습시킨 다는 것은 Maximum Likelihood Estimation 하는 것과 같은 말이다. 기존의 머신러닝 학습 과정 우리가 일반적으로 머신러닝을 처음 공부할 때, 아래와 같은 메커니즘으로 모델이 동작한다는것을 배웁니다. 학습데이터 x를 모델에 입력한다. 입력값 x가 모델 내의 파라미터(Weight and Bias)를 거쳐가며 예측값인 y_pred를 출력해 낸다. 이렇게 얻은 예측값 y_..
-
 AI 해커톤
5. [Model Centric] Anomaly Detection(feat. VAE)
이전 포스팅 1.Task : 해당 프로젝트에서 문제정의에 대한 내용을 다룹니다. 2. DataCentric : 주어진 데이터를 살펴보며, 데이터가 가지는 문제점을 찾아내고 인사이트를 얻는 과정입니다. 3. Classification & CAM : 부품 불량을 위해 분류 모델을 학습하고, 신뢰성을 확보하기 위해 CAM기법을 적용해 보는 과정입니다. 4. CAM 대시보드 개발 : 최적의 CAM 시각화를 얻기 위한 실험과 함께 대시보드를 개발하는 과정입니다. [널링 외의 요소] Anomaly Detection 앞서 DataCentric 편에서 압입과 미압입인 데이터에 대해서 살펴보고 그 결과, 정상 데이터만을 활용하는 이상치 탐지 방법론으로 해결하고자 했습니다. 이상치 탐지는 처음 접해보는 task였기에, 서..
AI 해커톤
5. [Model Centric] Anomaly Detection(feat. VAE)
이전 포스팅 1.Task : 해당 프로젝트에서 문제정의에 대한 내용을 다룹니다. 2. DataCentric : 주어진 데이터를 살펴보며, 데이터가 가지는 문제점을 찾아내고 인사이트를 얻는 과정입니다. 3. Classification & CAM : 부품 불량을 위해 분류 모델을 학습하고, 신뢰성을 확보하기 위해 CAM기법을 적용해 보는 과정입니다. 4. CAM 대시보드 개발 : 최적의 CAM 시각화를 얻기 위한 실험과 함께 대시보드를 개발하는 과정입니다. [널링 외의 요소] Anomaly Detection 앞서 DataCentric 편에서 압입과 미압입인 데이터에 대해서 살펴보고 그 결과, 정상 데이터만을 활용하는 이상치 탐지 방법론으로 해결하고자 했습니다. 이상치 탐지는 처음 접해보는 task였기에, 서..
-
 AI 해커톤
4.[Model Centric] CAM 대시보드 개발 (feat. Streamlit)
이전 포스팅 1.Task : 해당 프로젝트에서 문제정의에 대한 내용을 다룹니다. 2. DataCentric : 주어진 데이터를 살펴보며, 데이터가 가지는 문제점을 찾아내고 인사이트를 얻는 과정입니다. 3. Classification & CAM : 부품 불량을 위해 분류 모델을 학습하고, 신뢰성을 확보하기 위해 CAM기법을 적용해 보는 과정입니다. 최고의 CAM 시각화를 얻어내자 앞선 포스팅에서 분류 모델의 신뢰성을 위해 GradCAM을 적용해 봤습니다. 그 결과, 높은 성능에 대한 신뢰성을 어느 정도 확보할 수 있었죠. 단순히 신뢰성 확보를 위해 CAM을 적용해 본 거지만, 이 시각화 정보를 공장 측에도 제공해 주면 좋겠다는 생각이 문득 들었습니다. 단순히 어떤 불량인지 분류하는 걸 넘어, 불량의 위치정..
AI 해커톤
4.[Model Centric] CAM 대시보드 개발 (feat. Streamlit)
이전 포스팅 1.Task : 해당 프로젝트에서 문제정의에 대한 내용을 다룹니다. 2. DataCentric : 주어진 데이터를 살펴보며, 데이터가 가지는 문제점을 찾아내고 인사이트를 얻는 과정입니다. 3. Classification & CAM : 부품 불량을 위해 분류 모델을 학습하고, 신뢰성을 확보하기 위해 CAM기법을 적용해 보는 과정입니다. 최고의 CAM 시각화를 얻어내자 앞선 포스팅에서 분류 모델의 신뢰성을 위해 GradCAM을 적용해 봤습니다. 그 결과, 높은 성능에 대한 신뢰성을 어느 정도 확보할 수 있었죠. 단순히 신뢰성 확보를 위해 CAM을 적용해 본 거지만, 이 시각화 정보를 공장 측에도 제공해 주면 좋겠다는 생각이 문득 들었습니다. 단순히 어떤 불량인지 분류하는 걸 넘어, 불량의 위치정..
-
 AI 해커톤
3.[Model Centric] Classification & CAM
이전 포스팅 Task : 해당 프로젝트에서 문제정의에 대한 내용을 다룹니다. DataCentric : 주어진 데이터를 살펴보며, 데이터가 가지는 문제점을 찾아내고 해결방안을 도출하는 과정입니다. 모델의 흐름 불량 검출을 위해 사용한 모델 아키텍처는 위와 같습니다. DataCetric 편에서 말했듯, 널링 내의 요소(찍힘, 밀림, 이중선)와 널링 외의 요소(미압입)로 불량의 기준을 나누었고, 그에 따라 모델의 로직도 2가지로 나뉘게 되었습니다. 이번 포스팅에서는 널링 내의 요소로 찍힘과 밀림, 이중선, 정상을 분류해 내는 내용이 될 것이며, 이 과정에서 GradCAM기법을 사용하여 모델의 신뢰성을 확보하는 내용이 될 것입니다. [널링 내의 요소] Classification 부품 이미지에서 널링 내의 영역을..
AI 해커톤
3.[Model Centric] Classification & CAM
이전 포스팅 Task : 해당 프로젝트에서 문제정의에 대한 내용을 다룹니다. DataCentric : 주어진 데이터를 살펴보며, 데이터가 가지는 문제점을 찾아내고 해결방안을 도출하는 과정입니다. 모델의 흐름 불량 검출을 위해 사용한 모델 아키텍처는 위와 같습니다. DataCetric 편에서 말했듯, 널링 내의 요소(찍힘, 밀림, 이중선)와 널링 외의 요소(미압입)로 불량의 기준을 나누었고, 그에 따라 모델의 로직도 2가지로 나뉘게 되었습니다. 이번 포스팅에서는 널링 내의 요소로 찍힘과 밀림, 이중선, 정상을 분류해 내는 내용이 될 것이며, 이 과정에서 GradCAM기법을 사용하여 모델의 신뢰성을 확보하는 내용이 될 것입니다. [널링 내의 요소] Classification 부품 이미지에서 널링 내의 영역을..
-
 AI 해커톤
2.[DataCentric] 데이터의 문제점
Data Centric AI 최근 들어 딥러닝 계에서 Data-Centric AI라는 말을 자주 듣게 됩니다. 실제로 매년 기술의 성숙도를 표현해 주는 가트너의 하이프사이클(Hype Cycle)을 보면, Data-Centric AI는 많은 관심과 기대를 받고 있는 분야임을 확실히 알 수 있습니다. 그렇다면, 이렇게 떠들썩한 Data-Centric AI가 뜻하는 메시지는 뭘까요? 이름에서 알 수 있듯이 데이터의 관점으로 AI를 바라본다는 것입니다. 기존에는 모델 관점으로 AI가 많은 발전을 이뤄 왔었죠. 이를 Model-Centric AI라고도 합니다. 하지만 최근 들어 Model 보다는 Data의 관점에서 더 많은 연구와 작업이 필요하다고 대두되고 있습니다. 실제로 “머신러닝 성능을 향상시키기 위해선 모..
AI 해커톤
2.[DataCentric] 데이터의 문제점
Data Centric AI 최근 들어 딥러닝 계에서 Data-Centric AI라는 말을 자주 듣게 됩니다. 실제로 매년 기술의 성숙도를 표현해 주는 가트너의 하이프사이클(Hype Cycle)을 보면, Data-Centric AI는 많은 관심과 기대를 받고 있는 분야임을 확실히 알 수 있습니다. 그렇다면, 이렇게 떠들썩한 Data-Centric AI가 뜻하는 메시지는 뭘까요? 이름에서 알 수 있듯이 데이터의 관점으로 AI를 바라본다는 것입니다. 기존에는 모델 관점으로 AI가 많은 발전을 이뤄 왔었죠. 이를 Model-Centric AI라고도 합니다. 하지만 최근 들어 Model 보다는 Data의 관점에서 더 많은 연구와 작업이 필요하다고 대두되고 있습니다. 실제로 “머신러닝 성능을 향상시키기 위해선 모..
-
 AI 해커톤
1.[Task] 해결해야할 문제
안녕하세요 AI를 잘 다루고 싶은 Rimo입니다. 저는 딥러닝, 특히 Computer Vision에 관심이 많은데요, 해커톤이나 개인 프로젝트에서 실전과 같은 문제를 많이 다루고자 합니다. 이번 글에서는 제가 해커톤에서 수상한 내용을 기반으로 부품 불량 검출 모델을 개발한 과정에 대해 정리해 보고자 합니다. 하나의 성능지표를 높이는 데에만 집중했던 기존의 해커톤과는 달리 기획부터 모델링, 성능지표 선정까지 모두 본인이 스스로 진행해야 됐다는 점에서 나름 의미 있던 해커톤이었습니다. 이글이 도움 될만한 독자는 아래와 같습니다. AI 솔루션에 관심이 있는 모든 분들 특히 Classification, Object Detection, Anomaly Detection, XAI 분야에 관심이 있는 분들 MNIST가..
AI 해커톤
1.[Task] 해결해야할 문제
안녕하세요 AI를 잘 다루고 싶은 Rimo입니다. 저는 딥러닝, 특히 Computer Vision에 관심이 많은데요, 해커톤이나 개인 프로젝트에서 실전과 같은 문제를 많이 다루고자 합니다. 이번 글에서는 제가 해커톤에서 수상한 내용을 기반으로 부품 불량 검출 모델을 개발한 과정에 대해 정리해 보고자 합니다. 하나의 성능지표를 높이는 데에만 집중했던 기존의 해커톤과는 달리 기획부터 모델링, 성능지표 선정까지 모두 본인이 스스로 진행해야 됐다는 점에서 나름 의미 있던 해커톤이었습니다. 이글이 도움 될만한 독자는 아래와 같습니다. AI 솔루션에 관심이 있는 모든 분들 특히 Classification, Object Detection, Anomaly Detection, XAI 분야에 관심이 있는 분들 MNIST가..






















