
이전 포스팅
- 1.Task : 해당 프로젝트에서 문제정의에 대한 내용을 다룹니다.
- 2. DataCentric : 주어진 데이터를 살펴보며, 데이터가 가지는 문제점을 찾아내고 인사이트를 얻는 과정입니다.
- 3. Classification & CAM : 부품 불량을 위해 분류 모델을 학습하고, 신뢰성을 확보하기 위해 CAM기법을 적용해 보는 과정입니다.
- 4. CAM 대시보드 개발 : 최적의 CAM 시각화를 얻기 위한 실험과 함께 대시보드를 개발하는 과정입니다.
[널링 외의 요소] Anomaly Detection
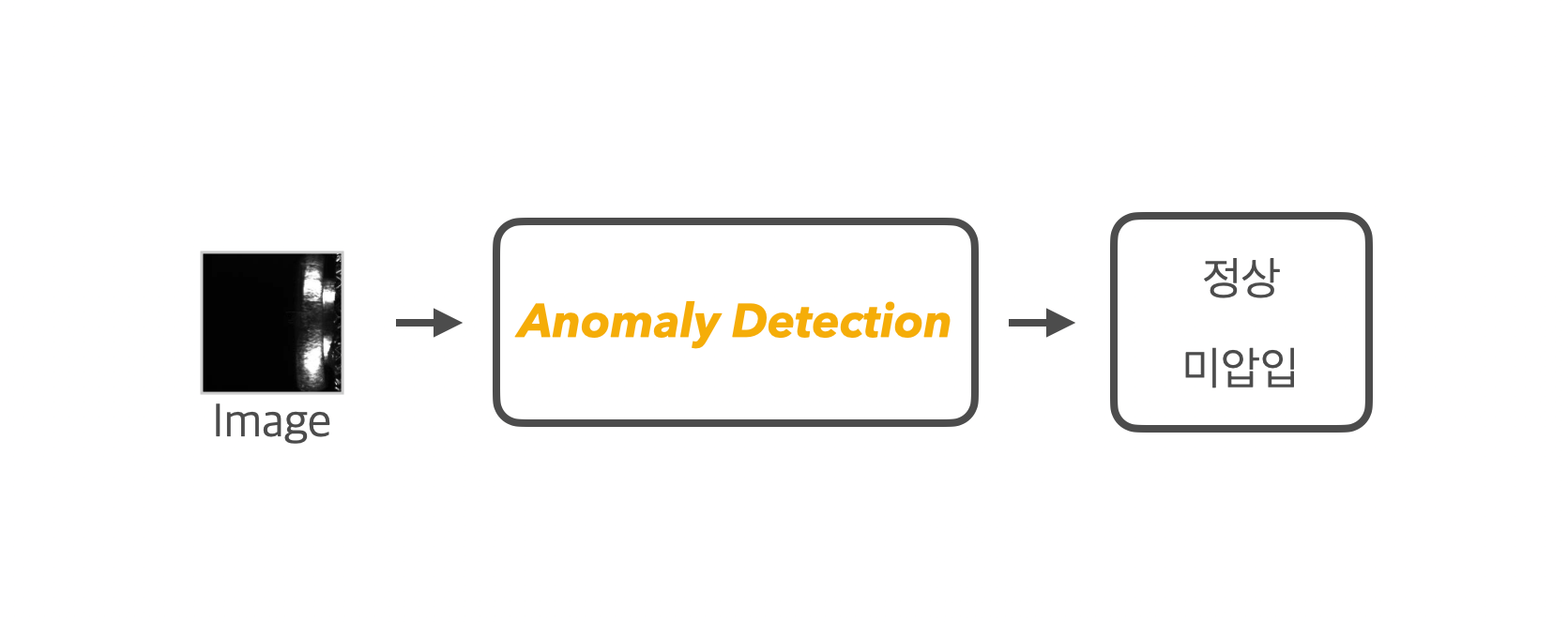
앞서 DataCentric 편에서 압입과 미압입인 데이터에 대해서 살펴보고 그 결과, 정상 데이터만을 활용하는 이상치 탐지 방법론으로 해결하고자 했습니다. 이상치 탐지는 처음 접해보는 task였기에, 서치를 통해 공부할 필요가 있었습니다. 딥러닝을 활용한 이상치 탐지에서 오토인코더(AutoEncoder) 모델을 자주 마주칠 수 있었습니다. AE를 살짝 변형한 여러 형제 모델들도 있었죠. 여러 서치를 해보며 최종적으론 VAE(Variational AutoEncoder) 모델을 활용하여 이상치를 탐지하기로 했습니다. AE와는 비슷한 듯 보여도, 전혀 다른 목적을 가진 VAE는 사실 너무나 방대한 내용이고, 짧은 시간 내에 이해하기 힘든 부분이 많았습니다. 꽤 오랜 기간 동안 여러 세미나 영상들과 글 덕분에 조금씩 조금씩 “직관적인” 이해가 가능했습니다. 아래 Reference에 제가 참고한 영상과 글들을 첨부해 놓도록 하겠습니다. VAE는 생성 모델을 공부하는 데 있어 꼭 한번 이해하고 넘어가면 좋을 것 같아, 후에 Generative항목으로 묶어 자세하게 기록해 보려고 합니다. (해당 포스팅에서는 VAE에 대한 자세한 이론은 다루지 않습니다.)
VAE를 활용한 Anomaly Detection
VAE는 생성모델의 한 종류로써, 학습과정에서 Train 데이터셋이 가지는 분포를 학습하게 됩니다. 그러면 적어도, Train 데이터셋이 가지는 분포 내의 데이터는 잘 생성할 수 있게 되죠. 반면, 해당 분포를 벗어난 데이터에 대해서는 옳게 생성해 낼 수 없게 됩니다. 이러한 점을 활용하여, 저는 VAE 모델에게 리벳이 잘 압입 된 정상데이터만을 학습시키려 합니다. 정상데이터에 대한 분포를 학습한 VAE모델이 정상 데이터에 대해서는 잘 생성하겠지만, 미압입된 불량 데이터에 대해서는 제대로 생성해 낼 수 없게 됩니다. 이 차이를 이용해서 정상과 미압입을 검출해 내려합니다. 해당 메커니즘을 단계별로 정리해 보면 아래와 같습니다.
1) 리벳 영역 추출
맨 처음 객체 탐지 모델로 Knurling의 영역을 추출해 낼 수 있었습니다. 이 영역을 Classification모델에 입력하여 널링 내의 요소에 대한 불량을 검출했었죠. 이제는 이 영역에서 리벳 방향의 220*220 영역을 임의로 추출해 내려합니다.

그러면 아래와 같이 리벳의 영역을 추출해 낼 수 있게 되죠. 추출해 낸 리벳의 영역은 아래와 같이 정상 1,173장, 미압입 356장을 얻게 됩니다. 전형적인 불균형 데이터지만, 우리는 정상 이미지만을 활용하여 모델을 학습시킬 것입니다.
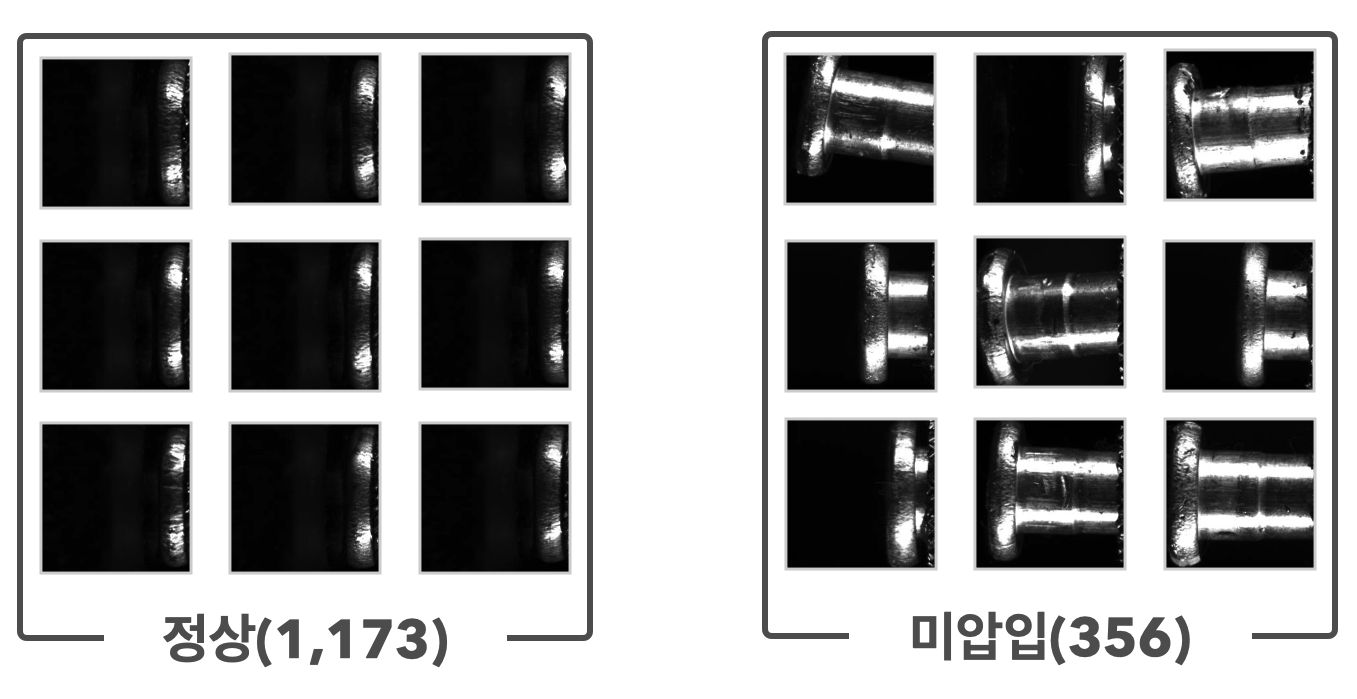
이렇게 리벳의 영역만 따로 추출해 내려는 이유가 있습니다. 압입과 미압입의 요소는 오로지 리벳의 영역만 보고 판단되어야 하기 때문이죠. 원본이미지에는 널리 영역, 부품의 기둥, 배경 등 판단에서 제외되어야 할 부분이 포함되어 있습니다. 이러한 요소들은 모델 성능에 악영향을 끼치게 될 노이즈가 될 것입니다.
2) VAE 학습
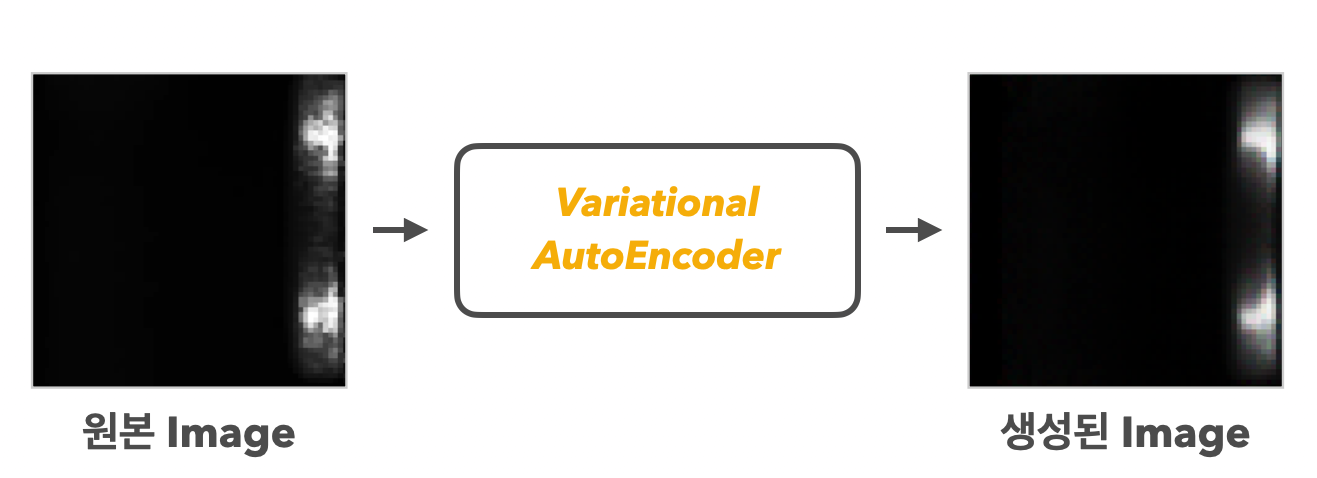
추출된 리벳 이미지 중 정상 데이터만을 VAE모델에 학습을 시키면, 아래와 같이 정상 데이터에 대한 분포를 잘 학습하여, 정상인 이미지를 잘 생성함을 볼 수 있습니다.
3) 정상 및 미압입 탐지
그렇게 생성된 이미지와 입력해 주었던 원본이미지와의 비교를 통해 잘 복원되었는지, 잘 복원되지 않았는지 판별을 하게 됩니다. 이 둘 사이의 오차를 구하기 위해 MSE(Mean Squared Error) 수식을 사용합니다. 해당 MSE값이 작다면 옳게 복원되었다는 뜻으로 정상이라 판단할 것이며, MSE값이 크다면 옳게 복원되지 못했다는 뜻으로 미압입이라 판단하게 될 것입니다.

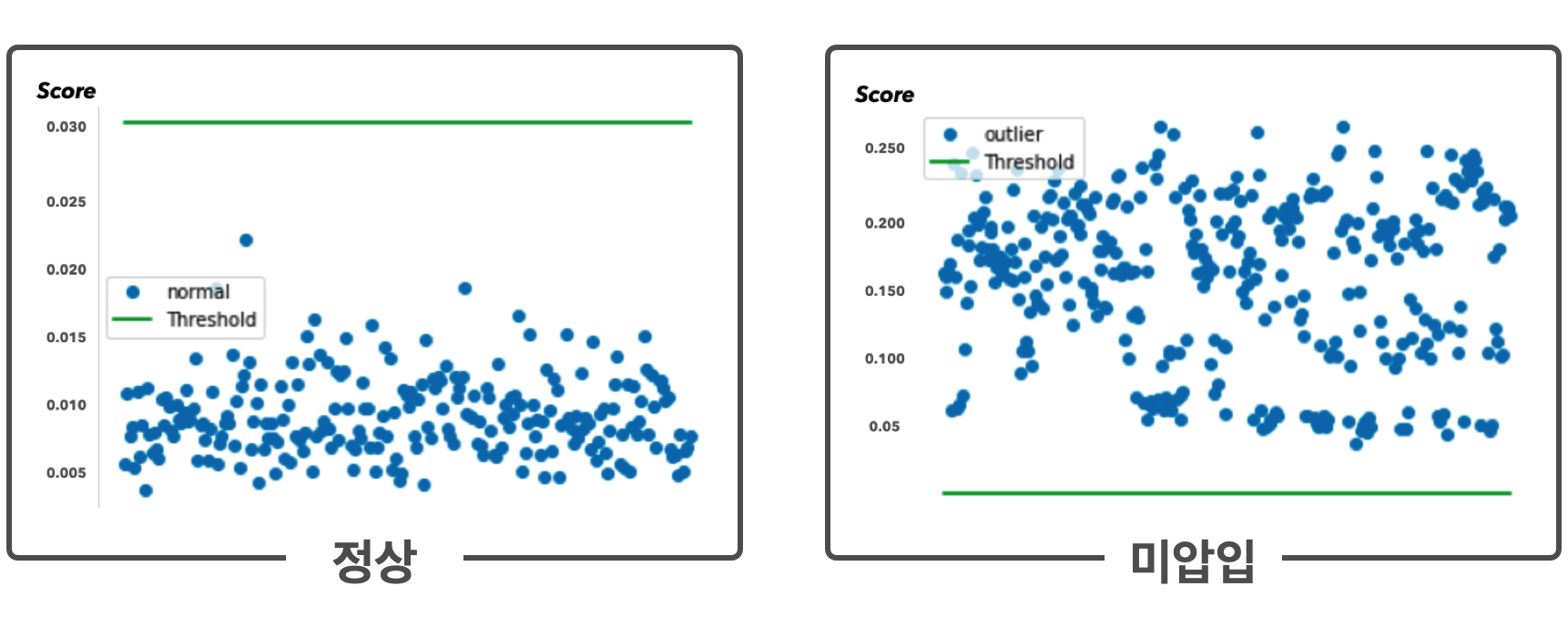
아래 이미지를 보면, 좌측의 정상 이미지에 대해서는 VAE모델이 옳게 이미지를 복원하고 있으며, 원본이미지와의 오차(MSE)가 굉장히 낮음을 확인할 수 있습니다. 반면, 학습시키지 않은 미압입 데이터에 대해서는 VAE모델이 제대로 생성하지 못하고 있으며, 당연히 원본이미지와의 오차가 크게 나타남을 볼 수 있습니다.
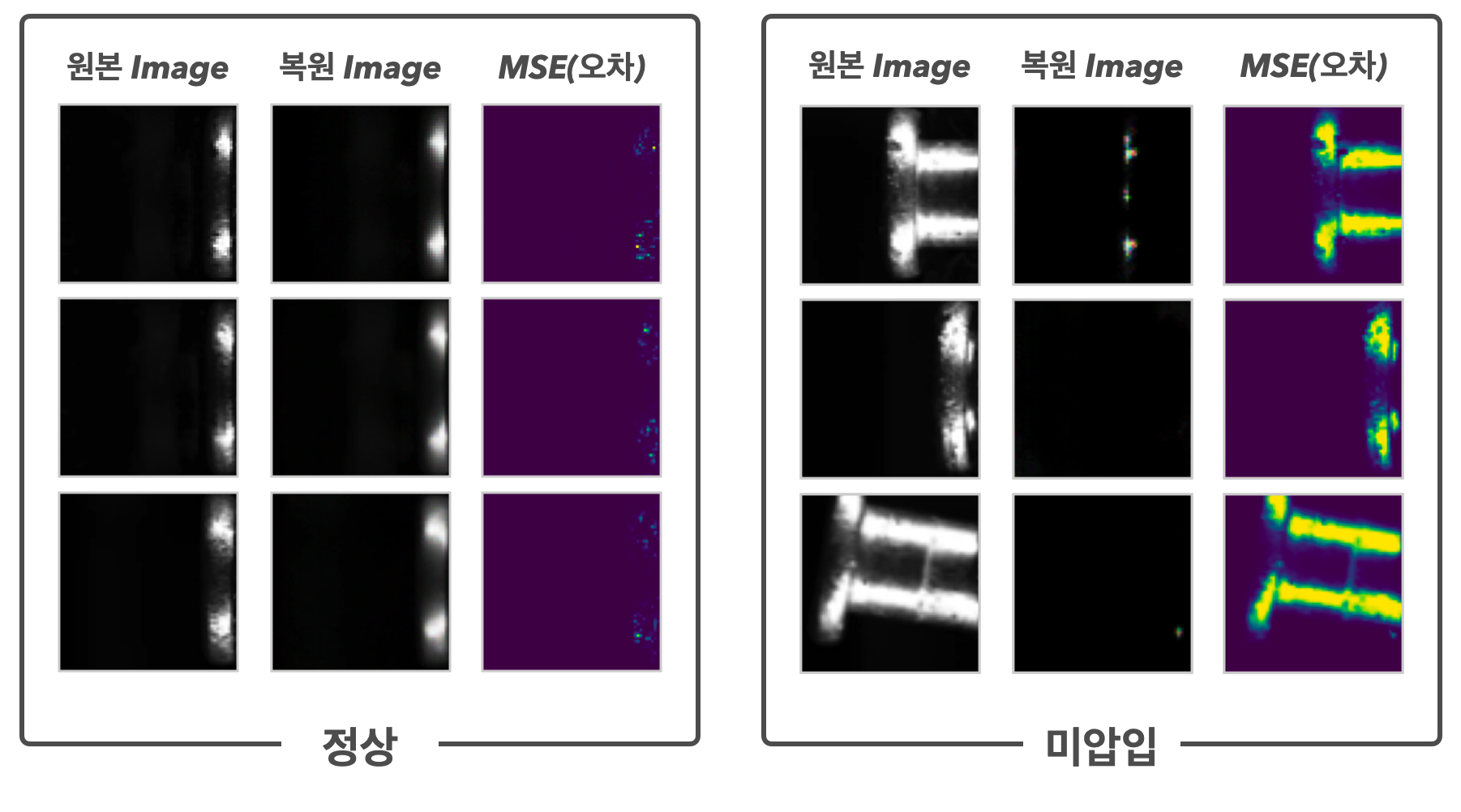
MSE 기준값을 0.003으로 두었을 때, 정상인 데이터에 대해서는 모두 해당 MSE기준값 보다 적은 오차값을 가지게 되고, 미압입 데이터는 기준값보다 모두 높게 측정됨을 볼 수 있습니다.
VAE로 이상치를 탐지했을 때의 이점
1. 비지도 학습 방법론이기에 특별한 라벨링 작업이 필요로 하지 않습니다. 공장 측에 시간과 비용을 아껴줄 수 있습니다.
2. 생산 공장의 특성상 데이터 불균형 현상이 생기기 마련인데, 정상인 데이터만 학습함으로써 해결할 수 있습니다.
3. 단순히 널링과 리벳 사이의 거리를 이용하여 검출하는 것보다 훨씬 더 안정적입니다. Validation에 있는 데이터셋에 한해서는 100%의 정확도를 가지고 있습니다.
마무리
VAE모델을 이해하기 위해서는 기존의 머신러닝 관점을 확률론적 관점으로 바라볼 수 있어야 합니다. 그리고 이는 후의 GAN과 Diffusion모델을 이해하는 데에 있어서도 좋은 자산이 됩니다. 이번 프로젝트를 통해 VAE를 활용하면서 Generative모델에 대해서 많은 관심을 가지게 되었고, Generative모델을 이해하기 위한 지식들을 정리해 보고자 합니다. 관련 포스팅은 해당 카테고리에서 진행할 예정입니다.
긴글 읽어주셔서 감사합니다.
Reference
'Tech > AI 해커톤' 카테고리의 다른 글
| 4.[Model Centric] CAM 대시보드 개발 (feat. Streamlit) (0) | 2023.03.10 |
|---|---|
| 3.[Model Centric] Classification & CAM (0) | 2023.03.07 |
| 2.[DataCentric] 데이터의 문제점 (1) | 2023.03.03 |
| 1.[Task] 해결해야할 문제 (0) | 2023.02.26 |