
이미지를 생성해 주는 인공지능이 처음 나왔을 때, 그 퀄리티에 놀란적이 있습니다. 2022년 4월, DALL·E 2가 세상에 공개되었을 땐, 이젠 웬만한 사람이 흉내 낼 수 없는 퀄리티를 보이기도 했습니다. 퀄리티면에서는 사람이 AI를 이기기란 어려운 일이 되어버렸습니다.
하지만 이런 발전에도 불구하고, 사용자의 의도를 정확히 반영하는 것은 여전히 어려운 문제로 남아있습니다. 사용자는 AI에게 프롬프트를 제공할 수 있을 뿐, 그 이후에는 AI가 확률적 알고리즘에 따라 이미지를 생성합니다. 때문에, 매번 다른 이미지를 생성하게 되고, 정확히 사용자가 원하는 그림을 얻기까지는 수많은 노력과 시간이 필요합니다. 한 가지 예시를 보겠습니다.
아래는 Stable Diffusion을 활용해 테니스를 치는 아이언맨을 생성해낸 그림입니다.

고도화된 prompt engineering 없이도 퀄리티가 꽤 높게 나옵니다. 퀄리티에 만족하지 말고 좀 더 원하는 형태로 생성해 봅시다. “포핸드 자세로 스윙하는 아이언맨” 사진을 생성하고 싶다면 어떻게 할까요?

위의 자세를 갖도록 생성하기 위해 prompt에 포핸드 자세를 추가할 수도 있겠지만, 포핸드 자세가 또 한 둘이어야 말이죠. 우리가 완전히 원하는 자세를 얻기는 힘들 것입니다. 자세의 복잡함을 prompt로 만 제어한다는 건 어려운 일입니다. 이러한 상황에서, 구체적인 요구사항을 반영하고 제어할수 있도록 해주는 것이 ControlNet의 역할입니다.
ControlNet이란?
Stable Diffusion은 사용자로 부터 받은 prompt만을 고려하여 이미지를 생성해 냅니다.
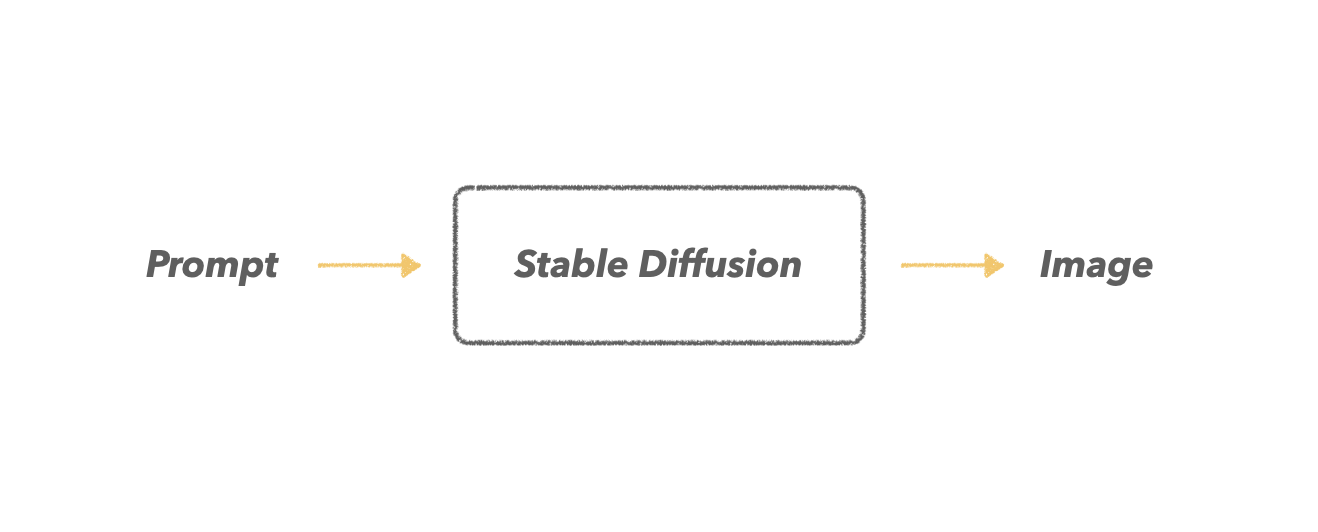
여기에 ControlNet을 결합하게 되면, prompt와 더불어 다른 유형의 조건을 추가로 제공해 줄 수 있게 됩니다. 그리고 이 추가적인 조건 덕분에, 우리는 보다 원하는 이미지를 얻을 수 있게 되죠.

이때 추가로 제공해 줄 수 있는“조건”은 꽤 다양한 종류가 있습니다. 아래 여러 활용 예시를 살펴보면 도움이 되실 거라 생각합니다.
1. OpenPose
앞서 언급한 “포핸드 자세로 스윙하는 아이언맨”을 한번 생성해 보겠습니다. 이를 위해 포핸드 자세를 갖춘 선수로 부터 자세를 추출하여 추가조건으로 부여하겠습니다. 이때 ControlNet의 openpose 모델을 활용할 수 있습니다.
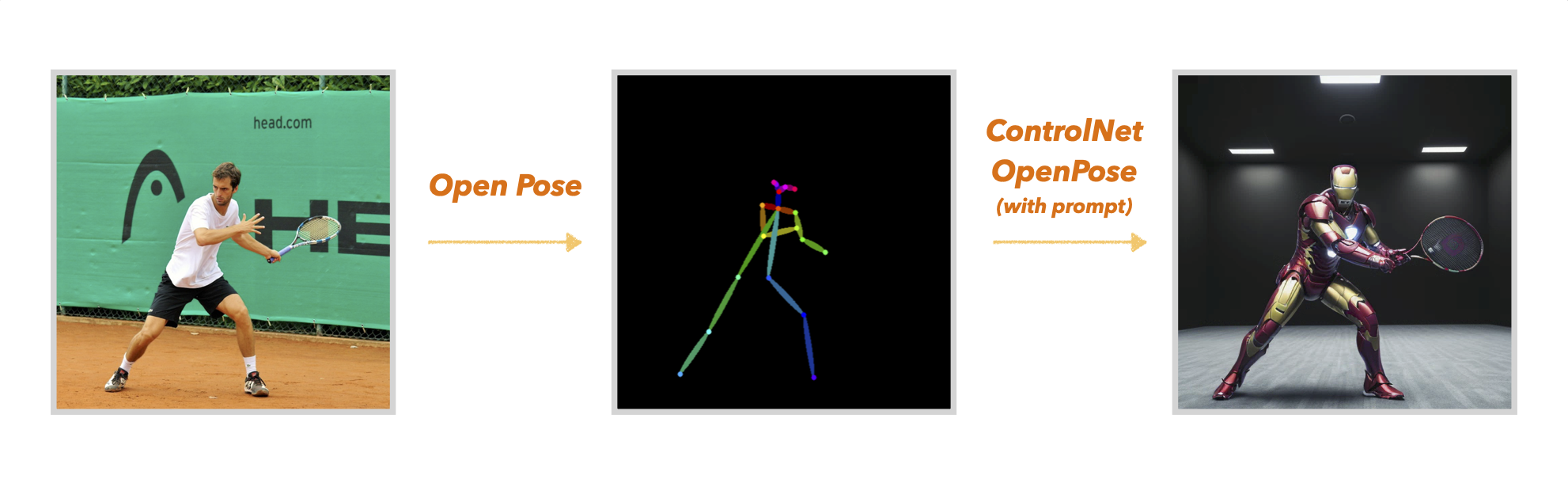
위의 사진처럼 ControlNet에 내가 원하는 자세를 openpose를 통해 추출하여 prompt와 함께 입력할 수 있습니다. ControlNet-openpose는 입력된 자세를 기반으로 이미지를 생성해 내게 됩니다.
2. Canny
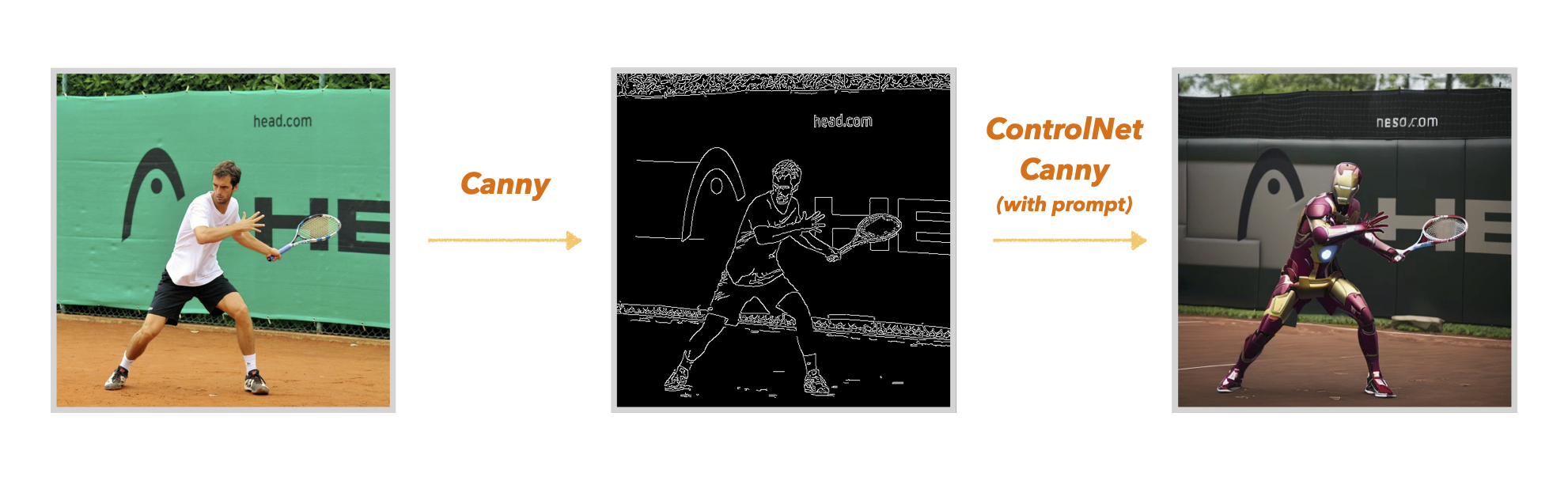
ControlNet-Canny는 입력 이미지의 윤곽선을 추가조건으로 받고, 이를 기반으로 이미지를 생성해냅니다.
3. Depth
ControlNet-Depth는 피사체의 depth조건을 활용하여 이미지를 생성해 냅니다.
위의 사진을 보면 선수의 윤관선을 따내고, 이를 기반으로 이미지를 생성함을 볼 수 있습니다. Canny가 입력 이미지의 전체 윤곽을 활용하다 보니, Openpose보다 선수의 자세를 더 잘 반영하는 경향이 있습니다. 하지만, 윤곽선을 따라 아이언맨을 생성하려다 보니 아이언맨의 슈트 퀄리티가 Openpose에 비해 좀 더 떨어지는 경향이 있는 것 같습니다.
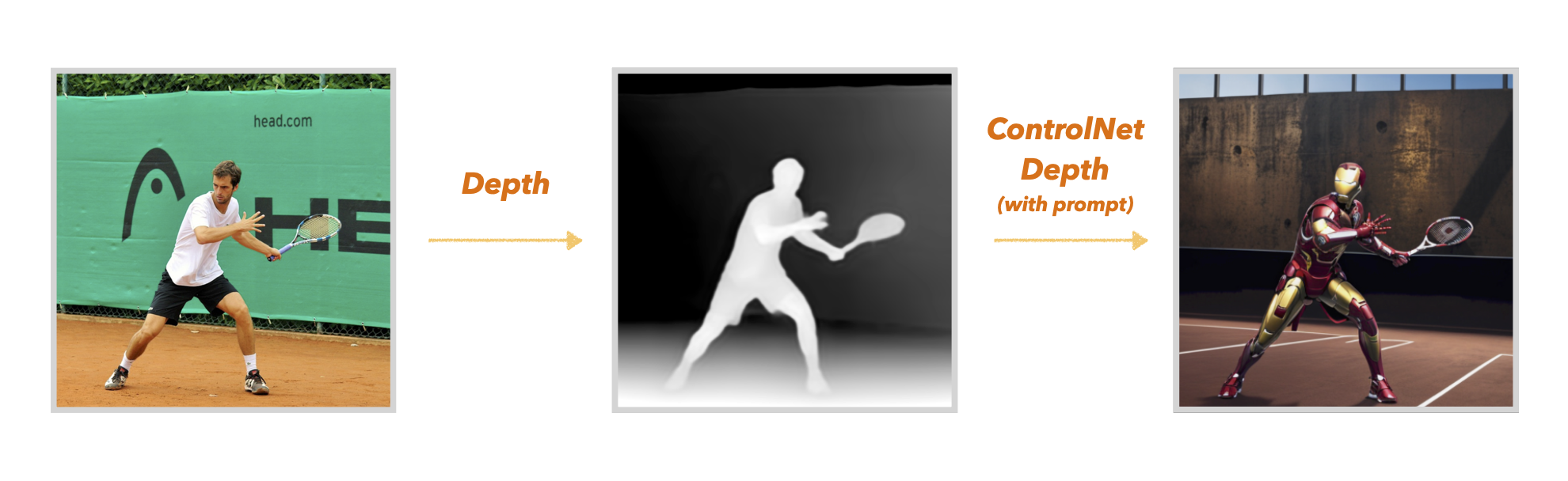
선수의 자세를 depth정보를 활용해서도 추출해 낼 수 있습니다. 주변의 배경도 마찬가지고요.
이렇게 ControlNet을 활용해 “포핸드 자세로 스윙하는 아이언맨”을 만들어 봤습니다. 이처럼 피사체의 자세를 조건으로 주고 싶을 때, 단순히 openpose의 직접적인 자세뿐 아니라 canny와 depth와 같은 요소들도 충분히 좋은 조건이 될 수 있습니다. 다양한 ControlNet의 기능을 적용해 보면서 최적의 조건을 찾아보면 되겠습니다. 이어서 ControlNet에 입력할 수 있는 또 다른 조건들을 간단히 소개드리겠습니다.
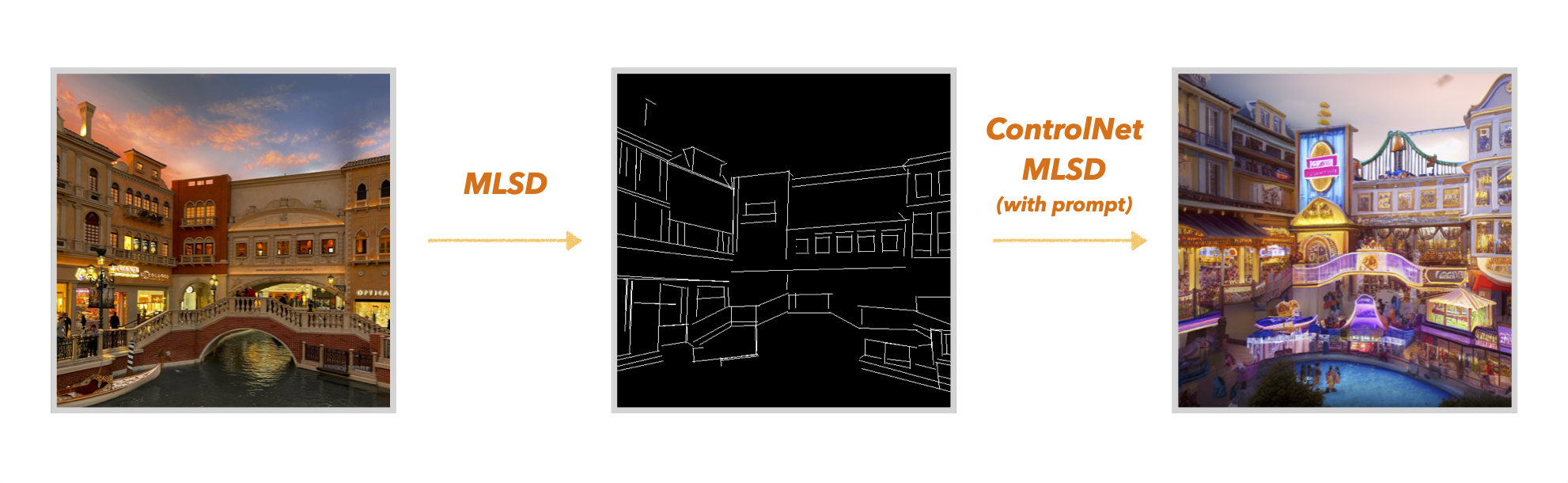
4. MLSD
MLSD는 입력 이미지의 직선 윤곽만 추출해 내어 조건으로 받아들입니다. 이런 특성 덕분에 건물과 인테리어 같은 요소에 찰떡입니다.
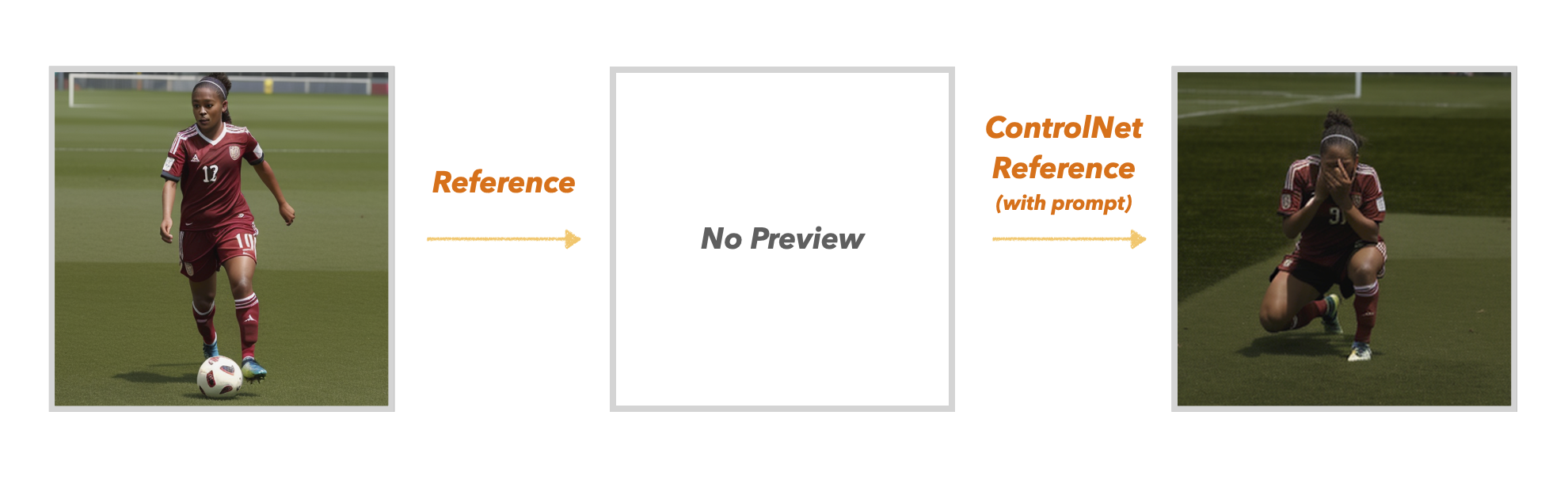
5. Reference-Only
Stable Diffusion을 활용하다 보면, 사진 속 사람이나 동물과 같은 피사체는 동일하게 두고, 다른 요소들만 변경하고 싶을 때가 있습니다. 기존 Stable Diffusion에서 img2img가 그 역할을 해왔지만, 노이즈와 왜곡이 꽤 있었습니다. ControlNet의 Reference는 입력이미지만을 참조하여 원하는 이미지를 좀 더 효율적으로 생성해 낼 수 있습니다. 아래는 기존의 여자 축구 선수를 참조하여, 해당 축구 선수가 울고 있는 모습 생성한 이미지입니다.
6. Segmentation
ControlNet-Segmentation은 참조 이미지를 Segmentation 하여 이미지 내의 객체들을 분할해 줍니다. Segmentation은 의미론적으로 분할해 주기 때문에, 어떤 영역이 사람인지, 배경인지, 의자인지 등 객체들을 이해할 수 있습니다. 아래의 예시를 보시면 쉽게 다가올 것입니다.

사람들이 회의하고 있는 사진을 참조하여 Segmentation 하였습니다. 전처리 된 사진을 보면 사람, 노트북, 테이블, 책 등이 잘 분할된 것을 볼 수 있습니다. 이를 기반으로 우주 비행사들의 마지막 회의 장면을 생성해 보았습니다.
7. Scribble
ControlNet-Scribble은 입력 사진으로부터 낙서 형태의 윤곽선을 그려줍니다. 이 Canny와 달리 낙서 느낌이기 때문에 생성되는 이미지가 더 창의적이고 자유도가 높게 나옵니다.

ControlNet에는 이 외에도 다양한 기능이 더 있습니다. 앞으로 더 나올 것이고요. 원하는 표현을 위해 다양한 기능들을 써보면서 자신만의 해석이 필요할 것 같습니다.
마무리
ControlNet이라는 주제를 떠나서, 이러한 생성 AI를 보면 어떤 생각이 드는지 궁금합니다. 저는 초등학생 때부터 그림 그리기를 좋아했고, 군대를 전역하고 나서는 취미로 일러스트를 배우며 그림을 그리곤 했습니다. 열심히 그린 작품들을 지인들에게 선물하며 기쁨과 보람을 느끼기도 했죠.
하지만 언젠가 이런 생성 AI를 보면 아쉬운 마음이 있기도 합니다. 밤새 만든 제 작품보다 3초 만에 만들어낸 AI의 작품이 객관적으로 더 이쁘거든요.. 취미로 그림을 그리는 저도 아쉬운데, 디자이너와 화가 입장에선 더 혼동스러울 거라 생각이 듭니다.
최근 StableDiffusion관련 세미나에 참여했는데, 한 강연자분께서 “이러한 시대에, 오히려 미술 기본기를 공부하는 게 어떨까요” 추천을 해주셨습니다. 참 아이러니 하지만, 또 맞는 말 같았습니다. 현재 StableDiffusion을 잘 활용하고, 커뮤니티를 주도하는 대부분의 사람들이 과거 디자인을 전공하신 분인 것만 봐도 알 수 있습니다. 디자인을 공부해 온 사람, 그림을 업으로 가져온 사람들은 이 AI를 어떻게 활용해야 할지에 대한 감과 센스는 일반인들보다 높을수 밖에 없기 때문이죠.
앞으로 AI가 점차 우리의 능력을 대신해 갈 테지만, 아이러니하게도 우리가 중요히 여겨야 할 부분은 각자의 분야에 대한 기본기와 AI활용에 대한 거부감을 없애는 것이 아닐까 합니다.
긴 글 읽어주셔서 감사합니다! 🤓
'Tech > Generative AI' 카테고리의 다른 글
| Rag : 나만의 LLM을 만들자 (0) | 2024.03.03 |
|---|---|
| GPTs, 나의 과거 프로젝트를 구현하다. (0) | 2024.01.21 |
| [StableDiffusion] Virtual Try On : AI로 원하는 옷 입히기 (1) | 2024.01.07 |
| AutoEncoder (0) | 2023.03.19 |
| 확률 관점으로 바라보는 머신러닝 (1) | 2023.03.15 |