모델 서빙이란
AI 서비스 관점에서, 모델을 잘 학습시키는 것 외에 해야 할 단계가 하나 더 있습니다. 바로 모델을 서빙하는 단계입니다. 잘 학습시킨 모델을 유저들이 사용할 수 있도록 실제 애플리케이션에 녹여내는 과정이라 보면 되겠습니다. 이 서빙 단계에서는 고려해 줘야 할게 한두 가지가 아닙니다. 유저들의 데이터는 어디에 보관할지, 모델 추론 시간을 실시간성으로 확보할 수 있을지, 유저들이 한꺼번에 몰릴 때는 어떻게 확장할지 등 엔지니어링 관점으로 고려해야 할게 수도 없이 많습니다. 그러한 과정을 잘 나타내주는 테크블로그 하나를 소개하고자 합니다. 이번 포스팅에서는 서빙단계에서 가장 기본이 되는 "컨테이너화"를 중점으로, 간단한 딥러닝 서비스를 컨테이너화하는 과정을 기록하고자 합니다.
딥러닝 서비스의 아키텍쳐
딥러닝 서비스로는 이전에 개발한 딥러닝 대시보드를 활용하려 합니다. 해당 대시보드를 좀 더 업그레이드하여, 아래와 같이 아키텍처를 구성하였습니다.
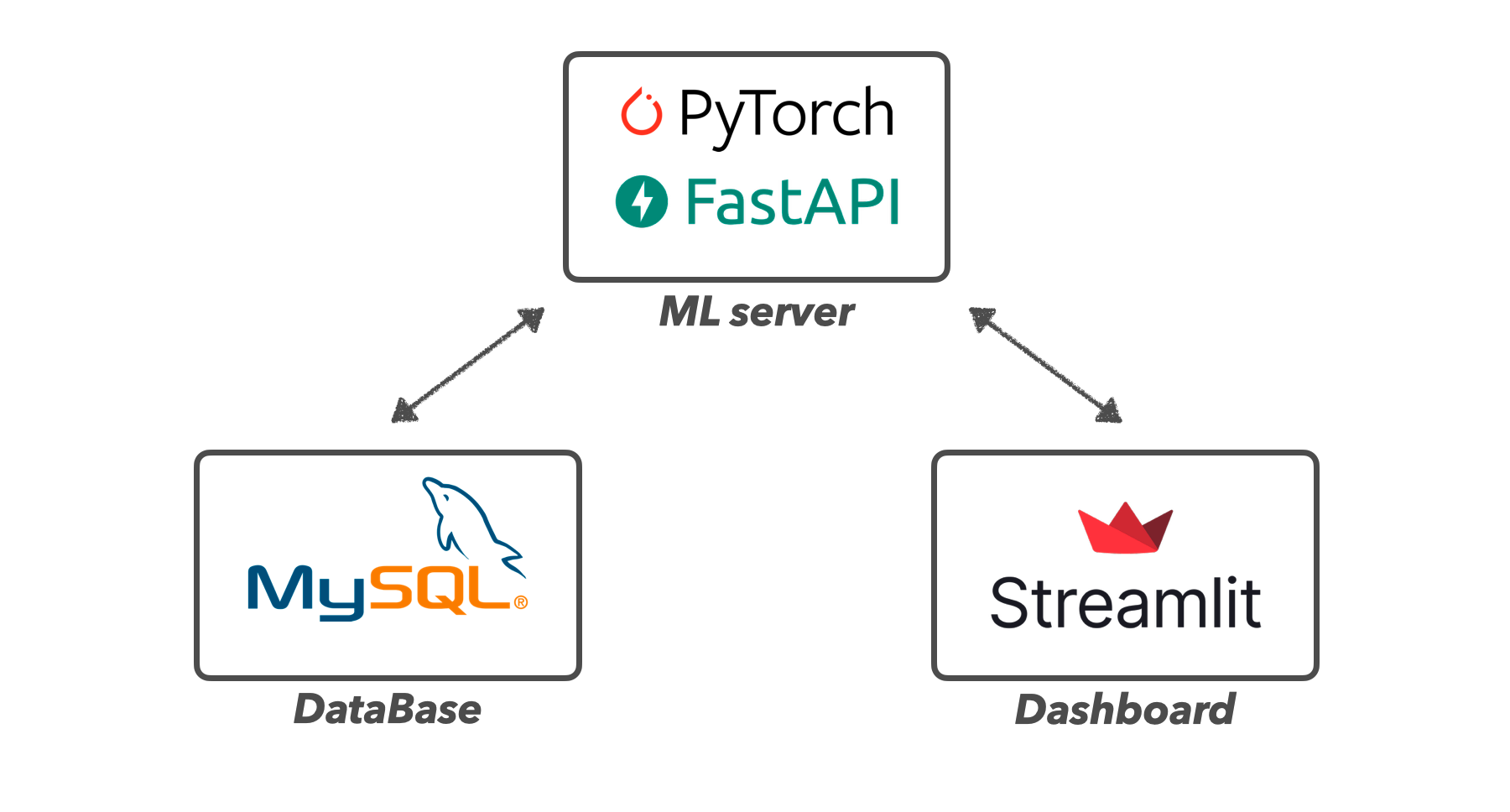
[ML server]
대시보드에 입력되는 실험 변수들을 RestAPI형식으로 제공받아, 해당 변수들이 적용된 모델의 추론이 이루어지는 단계입니다. 모델의 추론 값과 결과 이미지에 대한 정보를 데이터베이스에 저장한 뒤, 대시보드로 출력해 줍니다. 이때 모델은 Pytorch로 구현하였으며, python의 유용한 웹 프레임워크인 FastAPI를 통해 서버를 구현하였습니다.
[Dashboard]
어떤 실험을 진행할지 여러 변수들을 지정해 줄 수 있도록 UI를 구성하였으며, 해당 변수들을 딥러닝서버에 RestAPI형식으로 제공해 주게 됩니다. 그 후 해당 실험 결과를 시각화로 제공해 줍니다. 이때 대시보드의 UI는 python으로 쉽게 제작가능하며, 비교적 깔끔한 UI를 가진 Streamlit을 활용하였습니다.
[Database]
다른 변수들과의 실험결과를 비교하기 위해, 동일한 실험을 반복할 경우가 많습니다. 이럴 경우, 매번 모델을 통한 추론 결괏값을 받아오기 보다는, 한번 실험했던 결과는 따로 데이터 베이스에 저장해놓고, 불러올 수 있도록 구현하였습니다. 이를 위해, 실험에 대한 변수와 결과값 등 여러 로그를 저장할 수 있도록 관계형 데이터 베이스를 구축하였고, 오픈소스로 활용할 수 있는 MySQL을 활용하였습니다.

도커라이징
이제 위의 애플리케이션을 도커를 활용하여 컨테이너화 하려 합니다. 이때 어떤 기능 단위로 컨테이너화 할지 잘 설계할 필요가 있습니다. 막말로 위의 ML server, Dashboard, Database 등 모든 기능을 단 하나의 컨테이너로 패킹을 할 수 있겠습니다. 하지만 이렇게 하면 컨테이너를 운영하는 데 있어서 비효율적입니다. 만일 대시보드 UI의 미세한 코드 수정이 있다면, 이 작은 변화 하나 때문에 거대한 컨테이너를 다시 패킹해야 하는 일이 발생하기 때문이죠. 때문에 각 독립적인 기능 단위로 컨테이너화 하여, 이들의 상호적인 통신을 통해 서비스가 굴러갈 수 있도록 해줍니다. 이렇게 하면 전체 시스템의 중단 없이 필요한 부분마다 수정하는 게 용이해지며, 서비스 운영면에서 효율성이 생깁니다. 실제로 대부분의 IT기업들이 이러한 서비스 구조를 따르며, 굳이 용어로 따지자면 MSA(MicroService Architecture)라고도 합니다. 이러한 구조를 유념하여 제가 설계한 도커라이징 구조는 아래와 같습니다.
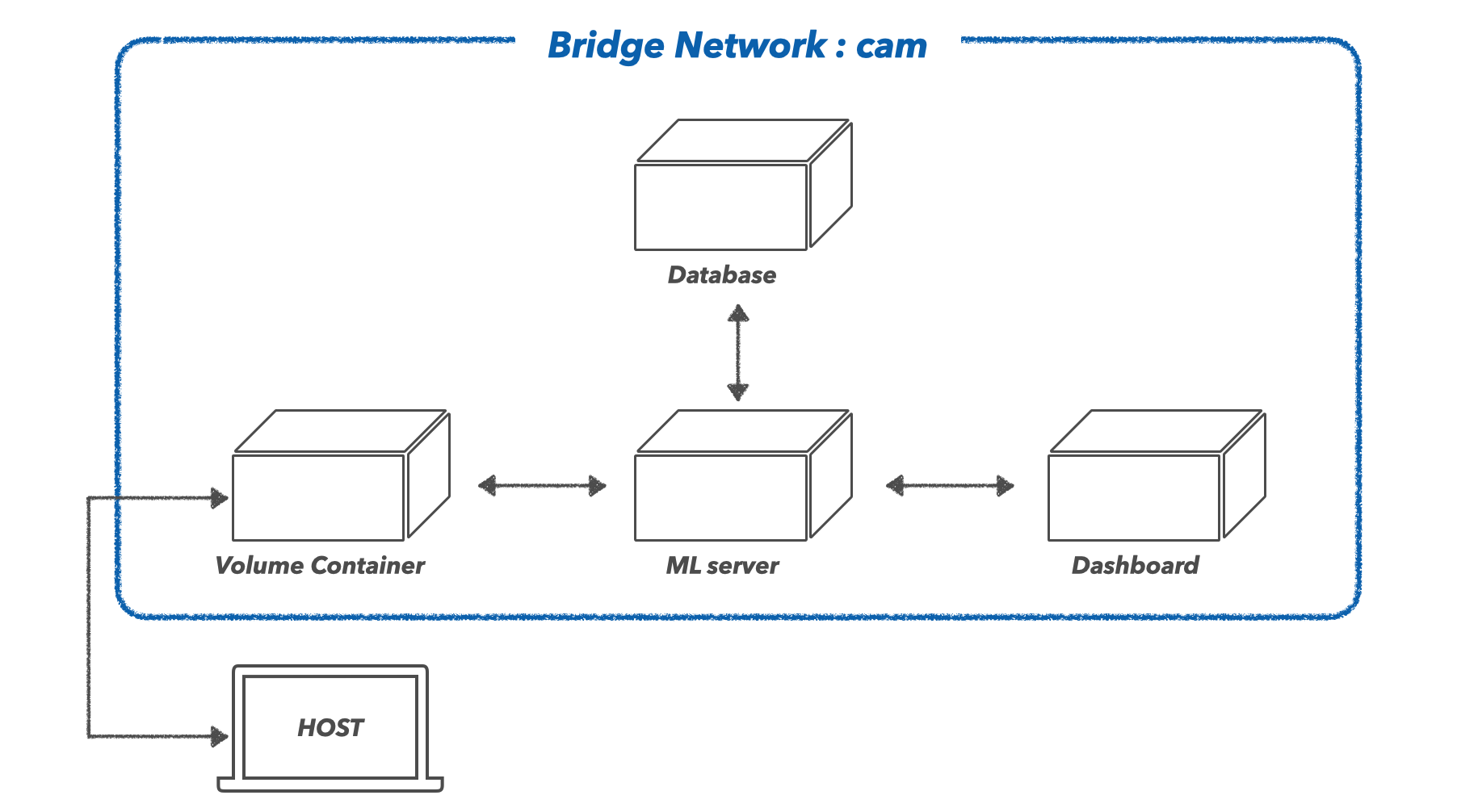
위의 구조에서 네트워크, VolumeContainer, ML server, Dashboard, Database 각각의 요소에 대해서 살펴보겠습니다.
1) 네트워크
위의 여러 컨테이너들이 서로 통신하기 위해, 도커 브리지를 따로 생성해 주었습니다. 브리지에 대한 정보는 이전 포스팅에서 다뤄본 적이 있습니다.
docker network create --driver bridge camcam이라는 이름을 가진 브리지 네트워크를 생성했습니다. docker inspect명령어로 cam 브리지를 살펴보면 172.19.x.x 대역대를 사용하고 있음을 볼 수 있습니다. 해당 브리지를 각 컨테이너에 연결해 주면 동일한 대역대를 사용하게 되며, 컨테이너끼리 서로 통신이 가능한 상태에 놓이게 됩니다.
$ docker inspect cam
[
{
"Name": "cam",
"Id": "34f6838e435578c2945c92ca576adcae3e0bd334742288bb681e45823dcc59dd",
"Created": "2023-04-28T01:10:06.350026097Z",
"Scope": "local",
"Driver": "bridge",
"EnableIPv6": false,
"IPAM": {
"Driver": "default",
"Options": {},
"Config": [
{
"Subnet": "172.19.0.0/16",
"Gateway": "172.19.0.1"
}
]
}이제 모든 컨테이너들이 서로 통신할 수 있는 하나의 네트워크 필드가 생성되었다 볼 수 있습니다.
2) Volume Container
호스트(내 컴퓨터)에 있는 특정 파일이 컨테이너와 공유될 필요가 있습니다. 예를 들어 실험에 필요한 모든 모델 weight 파일을 도커 이미지로 말아버리면 용량이 너무 커지게 되며, 추가로 학습된 모델이 있을 경우 매번 이미지로 다시 말아야 하는 불편함이 있습니다.(실제로 딥러닝 모델 한 개당 수 GB가 넘는 경우가 많습니다.) 때문에, 모델 파일은 호스트에 두고, 이 모델 파일들이 모여있는 폴더만 컨테이너와 공유하도록 하는 것이죠. 호스트의 볼륨을 컨테이너와 공유할 수 있도록 하는 다양한 방법에 대해, 이전 포스팅에서 다뤄본 적이 있습니다. 해당 애플리케이션에서는 호스트의 특정 폴더를 공유하는 Volume Container를 하나 생성하였습니다. 해당 컨테이너는 특정 기능 없이, 단순히 호스트의 볼륨만을 공유하는 기능을 하며, 추후 다른 컨테이너를 생성할 때는 호스트의 볼륨을 직접적으로 공유받지 않고, 이 Volume Container를 통해 간접적으로 공유받을 수 있도록 해줍니다.
docker run -it --name cam-volume --net cam -v /Users/rimo/Documents/paper:/app ubuntu이제 이 cam-volume이라는 컨테이너는 /app이라는 위치에서 호스트의 /Users/rimo/Documents/paper폴더를 공유받을 수 있게 되었습니다.
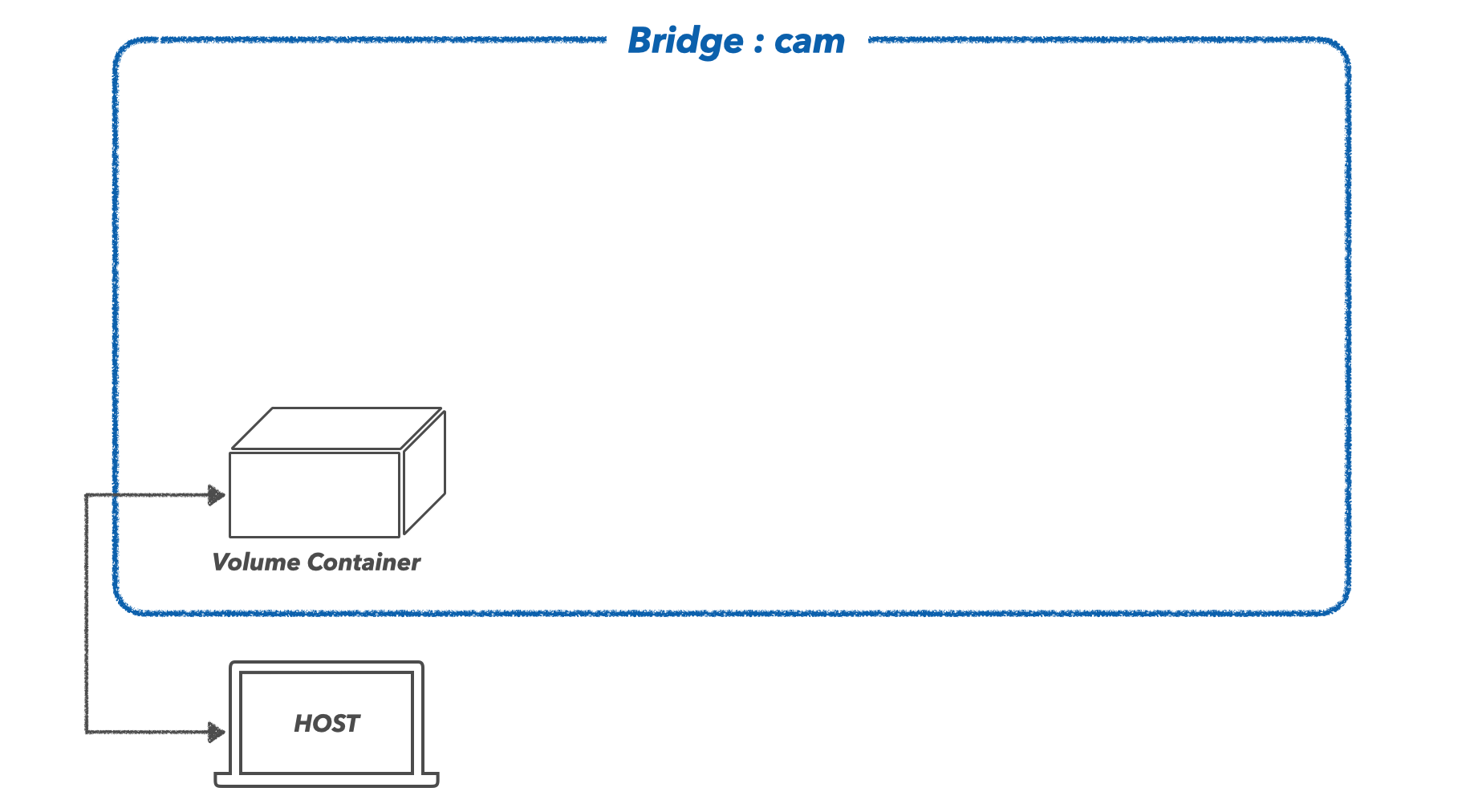
3) ML Server
학습된 모델을 불러와 추론을 진행하는 컨테이너입니다. 이때 실험할 모델의 종류, 이미지 종류, 전처리 종류 등 여러 실험변수들을 Dashboard로부터 제공받아야 할 텐데, 이를 RestAPI방식으로 제공받을 수 있도록 하기 위해 FastAPI프레임워크로 서버를 구성하였습니다.
[컨테이너 실행]
기본 이미지는 python:3.9-slim으로 하였고, 네트워크는 새로 생성한 cam이라는 브리지를 선택하고, cam-volume컨테이너와 볼륨을 공유하도록 하겠습니다.
docker run -it --name MLserver --net cam --volumes-from cam-volume python:3.9-slim /bin/bash
[모듈 설치]
모델과 서버를 위한 필요 라이브러리들을 설치하도록 하겠습니다. 저는 cpu로 모델을 추론할 것이기에 gpu를 위한 환경세팅은 하지 않았습니다.
apt update
apt install ffmpeg libsm6 libxext6 -y
apt install gcc -y
pip install opencv-python==4.6.0.66
pip install albumentations==1.2.1
pip install scikit-learn==1.1.3
pip install wandb
pip install fastapi
pip install uvicorn
pip install grad-cam
pip install torch==1.12.0 torchvision==0.13.1
pip install pymysql
pip install cryptography
[FastAPI 실행]
cd ./app/detector/classification
uvicorn main:app --reload --host=0.0.0.0 --port=30001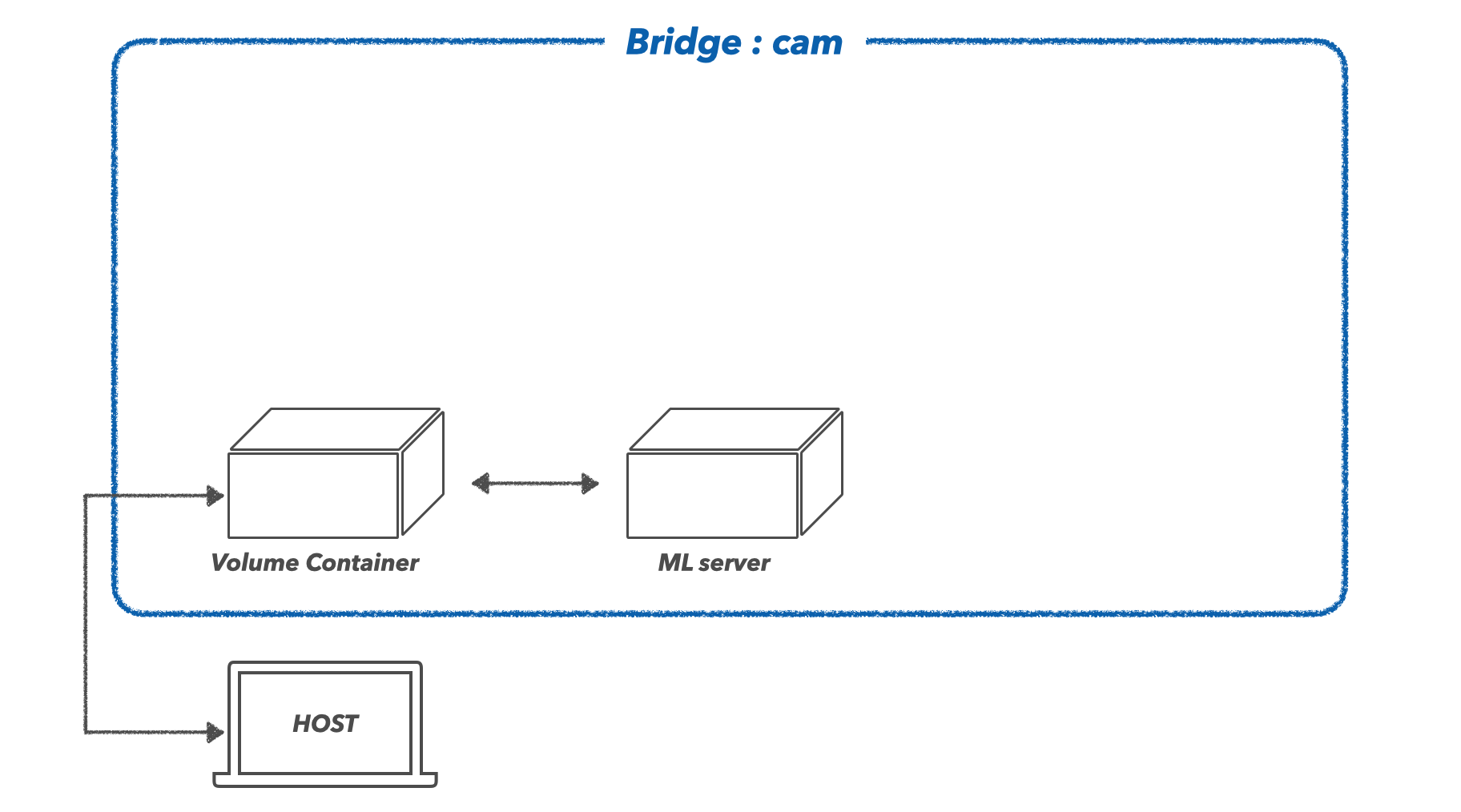
4) Dashboard
대시보드를 위한 컨테이너입니다. 유일하게 외부로 노출되어야 할 컨테이너입니다. 이를 위해 호스트에서 직접 접근할 수 있도록, 포트포워딩(-p 30002:30002)을 해주었습니다.
[컨테이너 실행]
docker run -it --name dashboard --volumes-from cam-volume --net cam -p 30002:30002 python:3.9-slim /bin/bash
[모듈 설치]
apt update
apt install ffmpeg libsm6 libxext6 -y
apt install gcc -y
pip install streamlit
pip install pandas==1.5.0
pip install opencv-python==4.6.0.66
pip install pycocotools
[대시보드 실행]
cd ./app/detector/classification
streamlit run streamlit.py --server.port 30002 --server.address 0.0.0.0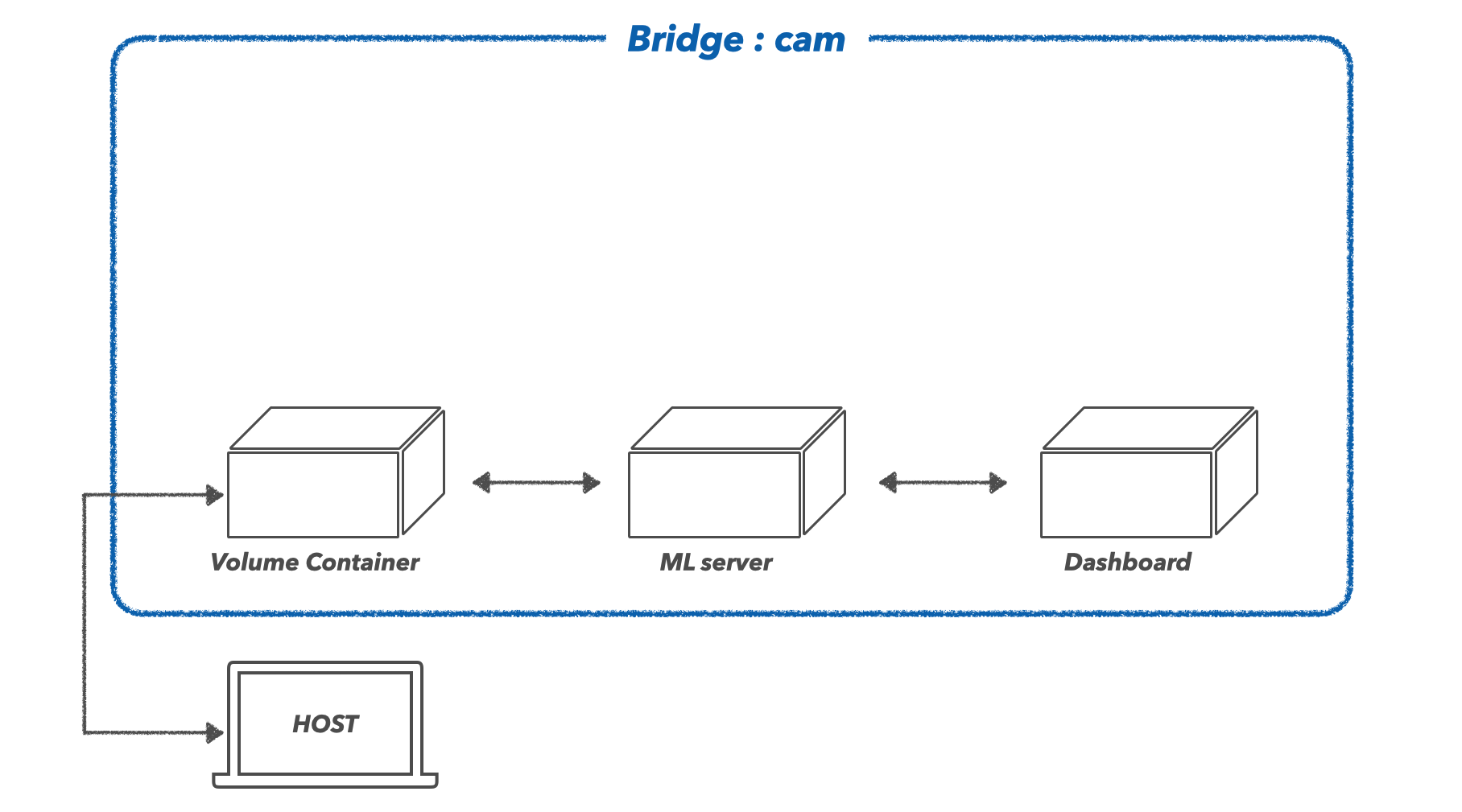
5) DataBase
ML server와 연결되어 있으며, 실험변수와 결과에 대한 로그를 저장하는 관계형 데이터베이스를 컨테이너로 구축하였습니다.
[컨테이너 실행]
docker run --name database -e MYSQL_ROOT_PASSWORD=<password> --net cam --volumes-from cam-volume -d mysql
docker exec -it database bash
[Table 생성]
$ mysql -u root -p
CREATE DATABASE CAM default CHARACTER SET UTF8;
USE CAM;
CREATE TABLE cam(id INT(11) NOT NULL AUTO_INCREMENT,
model_name VARCHAR(20) NOT NULL,
model_path VARCHAR(100) NOT NULL,
model_layer INT(11) NOT NULL,
transform VARCHAR(50) NOT NULL,
img_path VARCHAR(130) NOT NULL,
device VARCHAR(10),pred INT(11) NOT NULL,
hash_name VARCHAR(100) NOT NULL,
PRIMARY KEY(id));
마무리)
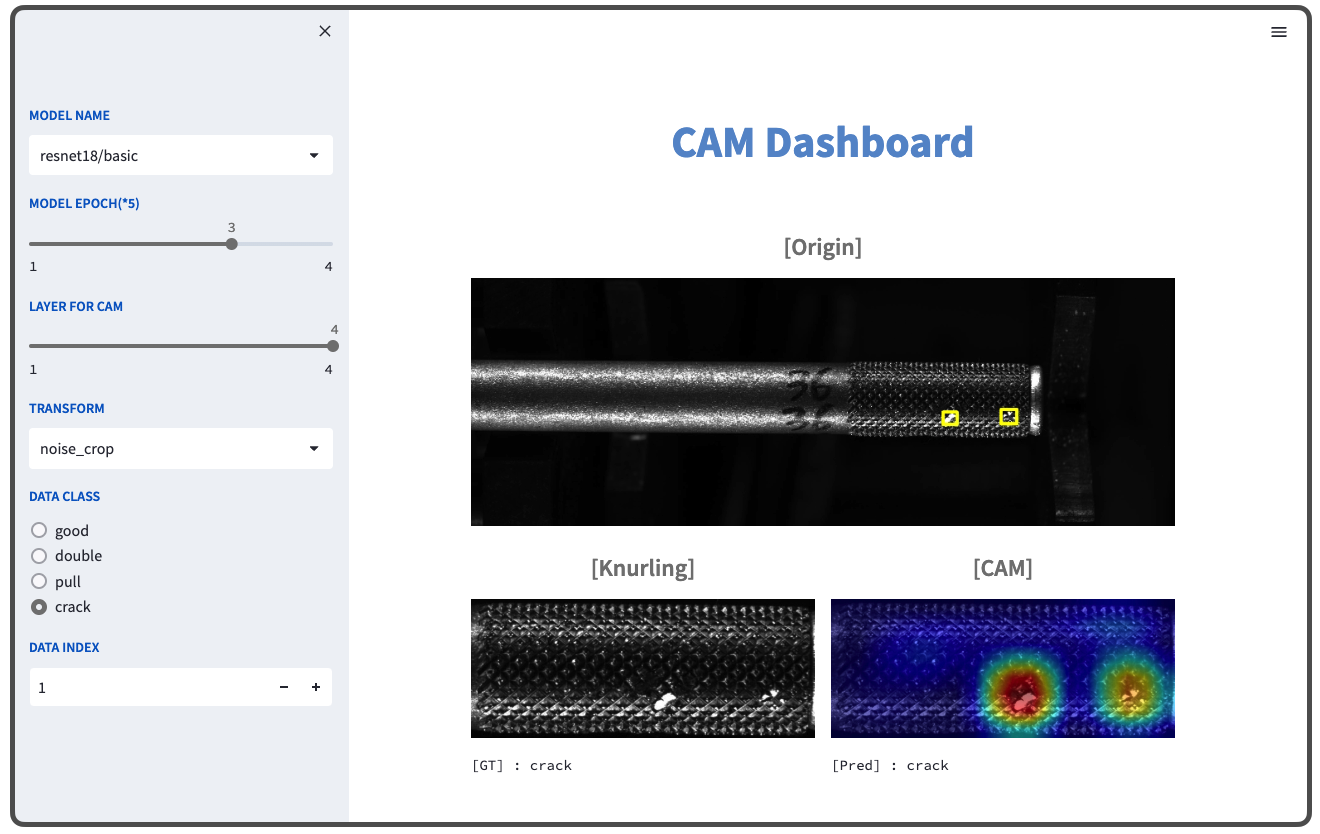
위의 모든 컨테이너가 서로 잘 통신하고 작동한다면, 원했던 대시보드의 기능을 볼 수 있을 것입니다. 확인해 보겠습니다. Dashboard 컨테이너는 호스트의 30002 포트와 연결되어 있기에, 웹 브라우저에서 localhost:30002에 접속하면 아래와 같은 대시보드를 볼 수 있습니다.

해당 대시보드를 보시면, 처음에는 결과까지 시간이 1초? 정도 걸리지만, 한번 확인했던 실험 변수에 대해서는 출력물이 곧바로 나오게 됩니다. 과거 실험에 사용되었던 로그들이 데이터베이스에 저장되어 있기에, 모델 추론을 불필요하게 하지 않도록 했기 때문입니다.
Next
이렇게 작은 딥러닝 서비스에 대해서 컨테이너화를 진행해 보았습니다. 하지만, 뭔가 아쉽습니다. 이렇게 간단한 서비스를 배포하고자, 매번 docker run 어쩌고저쩌고해야 하고, 네트워크를 연결해야 하는 등 부수적인 작업이 꽤 복잡하고 귀찮아 보입니다. 도커에는 이러한 과정을 효율적으로 다루기 위해 Docker Compose라는 녀석이 있습니다. 특정 파일 하나만 잘 작성해 놓으면, 위의 모든 작업이 단 한 줄의 명령어로 줄일 수 있게 됩니다. 다음에는 이 Docker Compose를 활용하여 위의 과정을 좀 더 효율적으로 압축해 보고자 합니다.
'Tech > Docker' 카테고리의 다른 글
| Udemy : Docker & Kubernetes 후기 (0) | 2024.03.31 |
|---|---|
| Docker Network : 호스트와 컨테이너를 위한 네트워크를 구성해보자 (0) | 2023.04.14 |
| Docker Volume : 컨테이너의 데이터를 영속적으로 보관해 보자 (0) | 2023.04.13 |
| Dockerfile & Commit : 나만의 애플리케이션을 Docker Image로 만들어 보자 (0) | 2023.04.09 |
| Docker의 구성 요소 : 이미지, 컨테이너, 레이어 (0) | 2023.04.03 |



