
어디에나 필요한 Virtual Try On
최근 친구가 취업에 성공했습니다.
사원증에 필요한 사진을 회사에 제출해야 했는데,
이것저것 바쁜 일이 많았던 친구는 일반 증명사진에 정장을 합성하기로 하죠.

당시 저는 StableDiffusion을 활용해, 옷을 변경하는 로직을 구상 중이었습니다.
마침 테스트로 활용할 실험군이 나타난 것이죠. 포토샵을 다룰 줄 몰랐지만, 선뜻해준다고 나섰습니다.
그 결과, 아래와 같이 정장을 입혀주게 되었습니다.

꽤나 마음에 들어 하던 친구는 이를 사원증으로 사용하게 되었죠.
서론이 조금 길었습니다.
위처럼, 디지털 환경에서 옷이나 액세서리를 가상으로 착용해 보는 기술을 "Virtual Try-On"이라 합니다.
꽤 많은 니즈가 있고, 이를 위한 많은 연구가 있어 왔죠.
이번 포스팅에서는 Stable Diffusion을 활용해서 어떻게 옷을 변경할 수 있었는지, 그 기술과 로직을 소개하겠습니다.
Let’s Go
아래와 같이 StableDiffusion으로 생성해 낸 가상의 축구선수 사진이 있습니다.

이제부터 해당 인물이 청자켓을 입은 프로필을 하나 만들어 보겠습니다.
이를 위한 파이프라인은 아래와 같습니다.
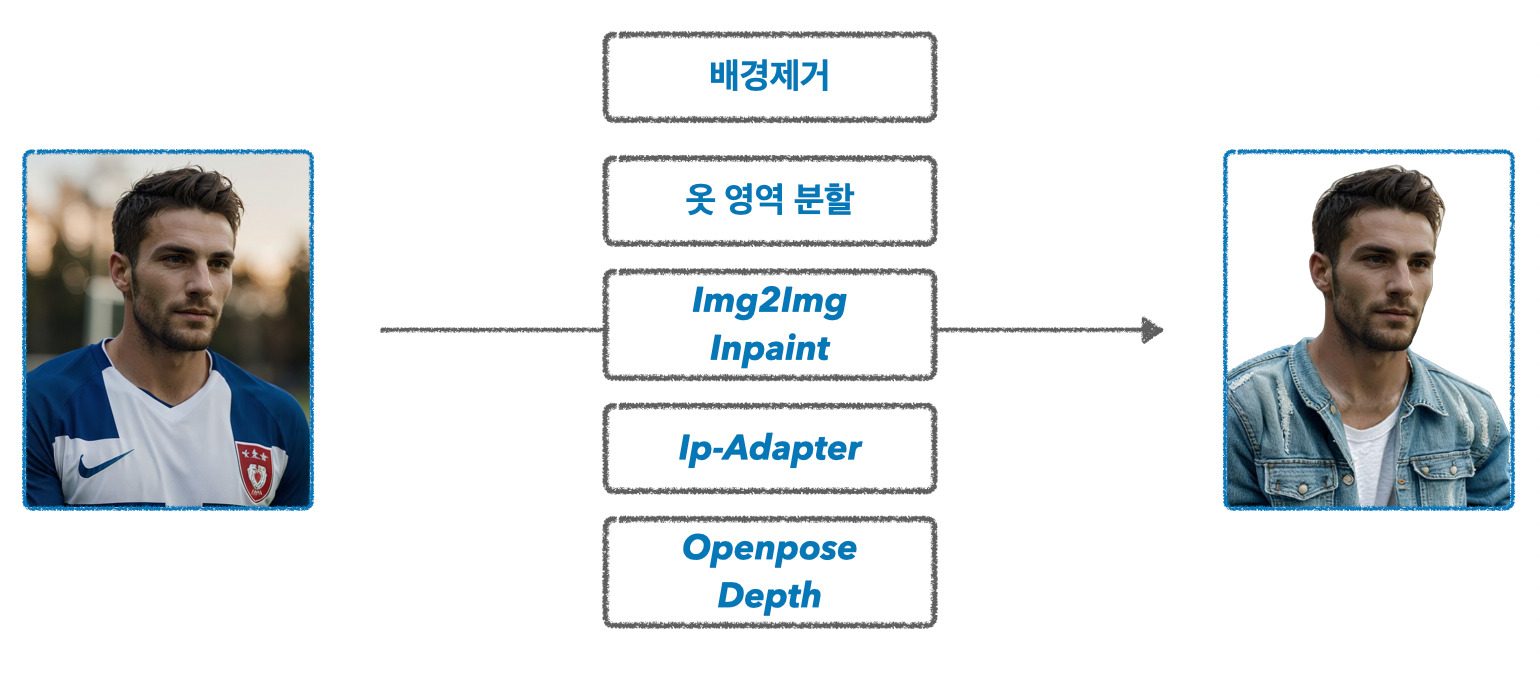
1. 배경제거 → rembg
프로필 사진을 위해선, 지저분한 배경부터 제거해야 합니다.
배경 제거를 위한 Segmentation 모델을 찾아보던 중, rembg라는 멋진 라이브러리를 발견했습니다.
rembg를 활용해 배경을 제거하는 일은 코드 몇 줄이면 가능했습니다.
저는 사진 속 영역에서 사람을 제외한 모든 영역은 다 배경으로 볼 것 이기에,
U2net_human_seg 라는 pre-trained 모델을 활용하여, 배경을 제거하였습니다.
(U2net은 Unet을 기반으로 하는 segmentation모델이며, 사물을 분할해 내는 데 사용되는 딥러닝 모델입니다.)

2. 옷 영역 분할 → rembg
착상을 변경하기 위해서는 우선 옷의 영역만을 인식해야 합니다.
사진 속 사람의 얼굴, 목, 손과 같은 요소들은 원본을 그대로 유지해야 하기에,
변경될 영역만을 미리 지정해 주는 것이죠.
옷의 영역을 분할해 내는 것은 배경을 제거하는 것과 크게 다르지 않습니다.
관심 영역이 배경이냐, 옷이냐의 차이죠.
동일하게 U2 net을 활용하였고, 옷의 영역을 학습한 pretrained 모델을 활용하여 분할하였습니다.
다만, 이번에는 컴퓨터가 인식할 수 있도록, 옷의 영역은 1, 나머지 영역은 0으로 이진화된 mask를 추출하였습니다.

3. StableDiffusion → Img2Img, Inpaint
이제부터는 StableDiffusion을 활용해, 원하는 옷을 입혀볼 차례입니다.
앞서 말했듯, 옷을 제외한 모든 요소들은 원본을 유지해야 합니다.
이를 위해 Img2Img의 Inpaint기능을 활용할 수 있습니다.
일반적으로 Img2Img는 소스 이미지를 참고하여, 전체적으로 새로 이미지를 생성해 냅니다.
반면, Img2Img의 Inpaint기능은 특정 영역은 유지하며, 나머지만 새로 생성해 냅니다.
아래의 도식화를 보면 Inpaint기능을 쉽게 이해할 수 있습니다.
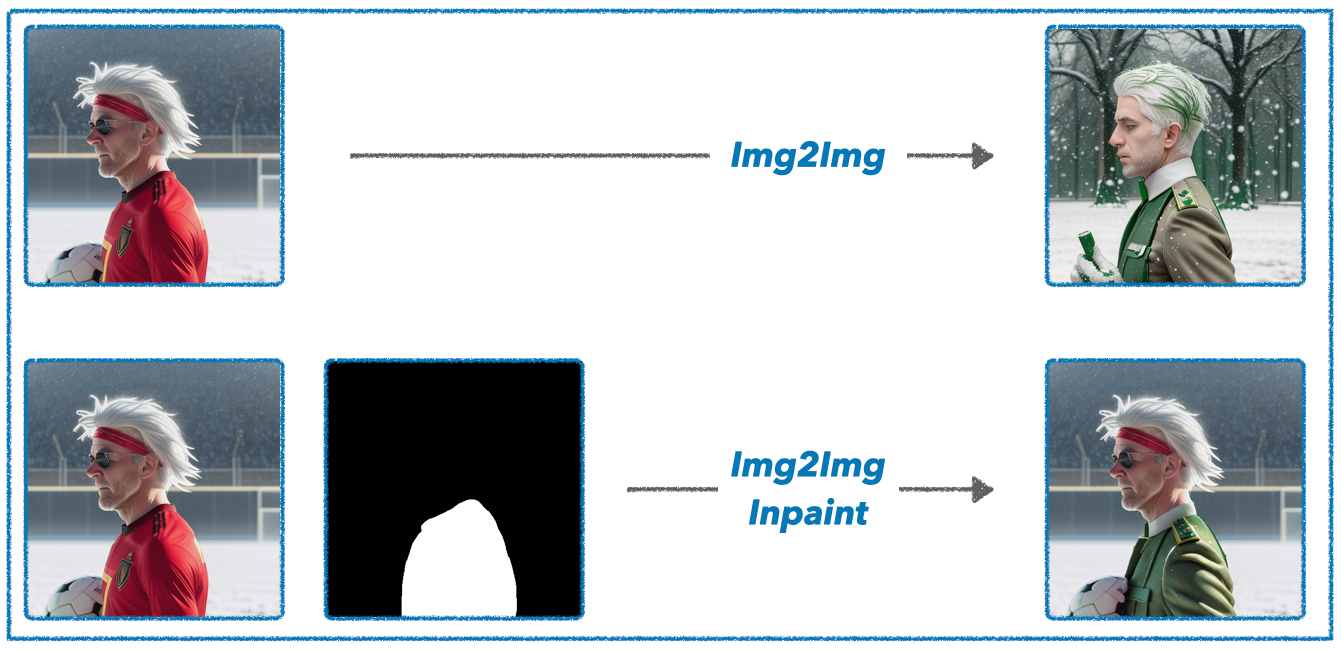
일반 Img2Img는 모든 영역을 새롭게 생성하는 반면, Img2Img의 Inpaint는 mask 된 영역만을 새롭게 생성하여, 기존의 얼굴과 배경의 요소들은 유지되고 있는 것을 확인할 수 있죠.
이때, 특정 영역을 지정해 줄 저 mask로 활용하기 위해, 앞서 옷의 영역만을 분할해 낸 것이죠.
4. StableDiffusion → Ip Adapter
우리가 입히고 싶은 옷은 청자켓입니다.
그런데, 청자켓의 종류가 얼마나 많을까요?

같은 청자켓이라도 이렇게 다양한 옷들이 있습니다.
StableDiffusion에게 단순히 프롬프트로 “청자켓”을 쥐어주면,
저 수많은 청자켓들 중 가장 꼴리는? 청자켓을 생성해 주겠죠.
이는 우리가 원하는 것이 아닙니다.
그렇다고 우리가 원하는 청자켓의 세부적인 모습을 text 프롬프트로 모두 전달해 주기에는 한계가 존재합니다.
이러한 문제점을 Ip Adapter가 해결해 줄 수 있습니다.
이미지가 천 마디 말보다 낫다. 라는 말이 있죠.
무언가를 설명할 때, 말로만 표현하기에는 한계가 있습니다. 그리고 말은 항상 오해를 불러일으키죠.
사람들이 상황을 설명 할 때, 그림을 선호하는 이유기도 합니다.
StableDiffusion에게 우리가 원하는 것을 text 뿐 아니라, Image로 알려줄 수 있다면 얼마나 좋을까?..
이것이 Ip Adapter의 존재 이유입니다.
Ip Adapter는 텍스트뿐 아니라, 이미지를 prompt로 제공하여 이를 참고하여 생성해 줄 수 있도록 해줍니다.
수많은 청자켓 중, 우리가 정확히 원하는 청자켓 이미지를 Ip Adapter를 활용해 prompt로 던져줘 보면,
아래와 같은 결과가 나옵니다.
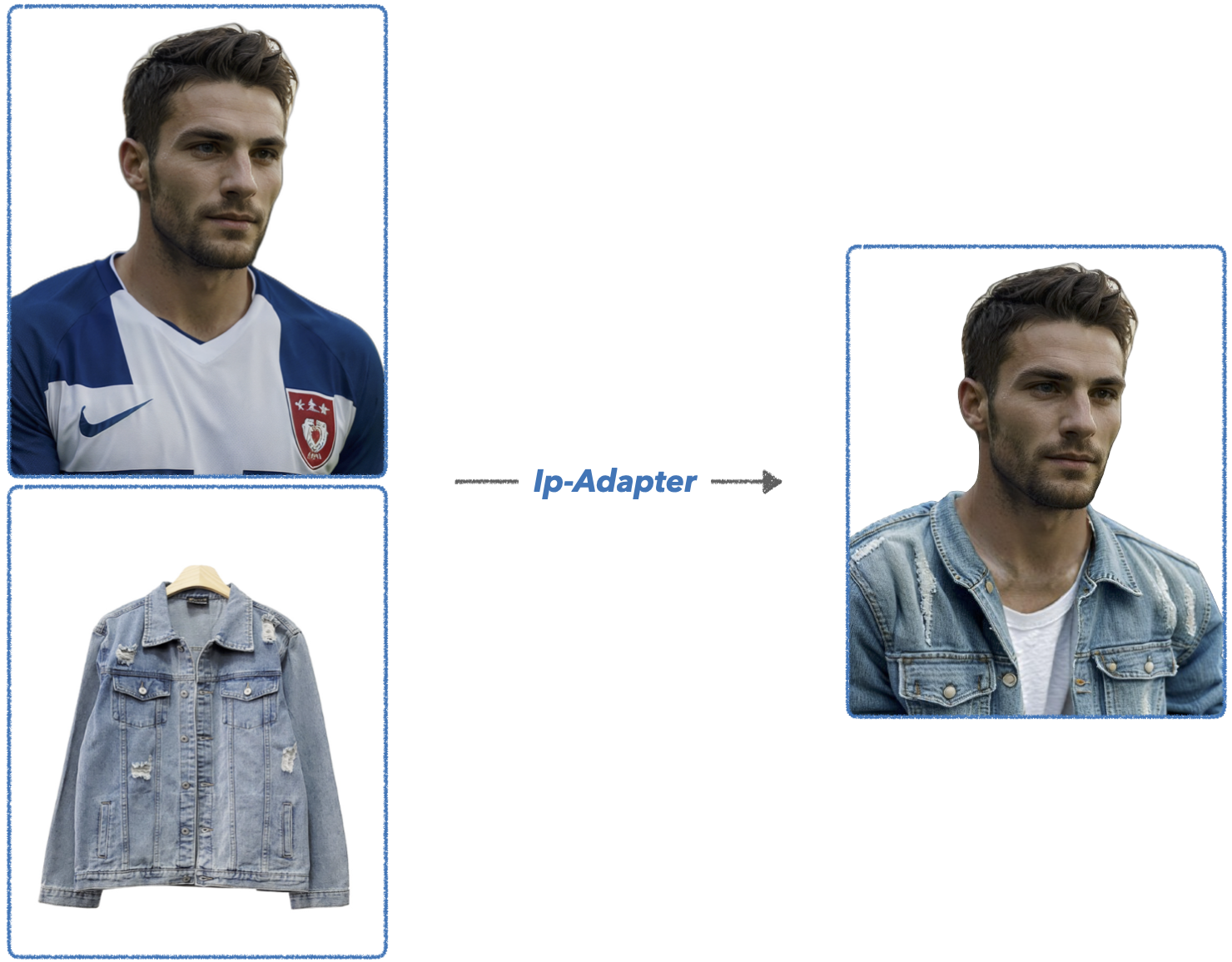
이는 귀만 달린 화가에게, 눈을 선물해 준 상황이라 볼 수 있습니다.
참 고마운 녀석이죠.
5. StableDiffusion → Openpose, Depth
여기서부터는 부가적인 트릭입니다.
원하는 옷의 스타일은 반영했지만, 해당 옷이 신체의 핏과 맞지 않다면 어색함이 생깁니다.
신체의 사이즈와 골격, 방향등을 고려하여 옷을 입힐 수 있다면 훨씬 더 자연스러울 테죠.
ControlNet의 OpenPose와 Depth가 이를 위한 해결책이 될 수 있습니다.
ControlNet에 대한 설명은 해당 글을 참고해 주시면 감사하겠습니다.
(사실 위의 IP Adapter도 ControlNet의 한 종류에요!)

이렇게 OpenPose와 Depth의 정보를 통해, 옷이 입혀질 공간과 뼈대를 부가적으로 제공해 주면
StableDiffusion은 조금 더 사진 속 인물에 자연스러운 옷을 생성해 줄 수 있습니다.
Gallery
이렇게 위의 모든 파이프라인을 구성해서 아래와 같은 결과물들을 얻을 수 있었습니다.



한계점이 있지만, 돌파구도 있다.
- 여전히 복잡한 옷들을 입혀주진 못합니다.
- 글자나 숫자가 있는, 복잡한 패턴을 가진 옷에 대해서는 반영을 잘 못합니다. 위의 예시들처럼 무늬가 없는 단순한 옷차림에 대해서는 웬만한 포토샵의 합성만큼이나 자연스러운 결과물을 내줍니다만, 복잡한 패턴까지는 완벽하게 반영해 주진 못합니다.
- 자동화하기에는 무리가 있습니다.
- 위의 로직대로 서비스하기에는 자동화 관점에서 문제가 있습니다. StableDiffusion에는 프롬프트와 더불어 수많은 HyperParameter들이 있는데, 각각의 상황마다 적합한 parameter가 다 다르죠. 또한 생성 AI는 어디까지나 확률 모델입니다. 내가 원하는 결과물을 얻기까지는 n번의 시도가 필요한 것이죠.
위의 여러 한계점들이 있지만, 최근 엄청난 기사를 접하게 되었습니다.
알리바바의 OutfitAnyone이라는 모델입니다.
아래는 해당 모델의 데모 이미지입니다.

위의 데모를 보면, 옷의 스타일뿐 아니라 구체적인 글씨나 액세서리도 모두 잘 반영하고 있는 모습을 볼 수 있습니다.
아직까진 코드를 공개하진 않았지만,
추후 오픈소스로 공개된다면 현재 저의 로직보다 더 강건한 로직을 얻을 수 있을 것 같습니다.
그럼 그날을 기대하며, 오늘 포스팅을 마무리하도록 하겠습니다.
긴 글 읽어주셔서 감사합니다!
'Tech > Generative AI' 카테고리의 다른 글
| Rag : 나만의 LLM을 만들자 (0) | 2024.03.03 |
|---|---|
| GPTs, 나의 과거 프로젝트를 구현하다. (0) | 2024.01.21 |
| [Stable Diffusion] ControlNet이란? ControlNet의 종류 (1) | 2023.09.16 |
| AutoEncoder (0) | 2023.03.19 |
| 확률 관점으로 바라보는 머신러닝 (1) | 2023.03.15 |