
PDF를 잘 읽는 게 중요한 이유
RAG(Recurrent Attention-Gated) 시스템을 구성하기 위해 가장 먼저 해야 할 작업은 문서를 텍스트 형태로 로드하는 작업이에요. 만약 문서의 종류가 Excel이나 Code 파일 같이 정형화된 파일일 경우, 텍스트로 변환하는 과정이 비교적 수월할 수 있습니다. 하지만, PDF 같이 비정형 파일들은 텍스트로 변환할 때 여러 가지 고려사항이 필요합니다. 아래는 PDF 파일을 단순히 텍스트로 변환한 예시예요.

위의 결과를 보면 PDF 내의 텍스트는 잘 불러온 것처럼 보이지만, 글의 단락과 구성이 반영되어 있지 않고 표의 정보도 깨져 있음을 볼 수 있어요. 사람에게 우측과 같이 텍스트만 제공하면, 정보를 제대로 파악하지 못할 가능성이 큽니다. 이는 LLM(Large Language Model)도 마찬가지예요. 이러한 변환 오류는 RAG의 성능에 부정적인 영향을 미칠 수 있습니다.
현대자동차 챗봇을 구현해 보며 PDF를 로드하는 과정에서 제가 시도했던 방법들과 그 결과물들을 공유하려고 합니다.
1. PDF를 마크업 언어로 추출하자
마크업 언어란?
마크업 언어란, 문서의 형식이나 구조를 명시하기 위한 규칙을 가진 언어입니다. 대표적으로 Markdown과 HTML이 있죠. 아래의 예시를 보면 마크업 언어를 쉽게 이해할 수 있을 거예요.
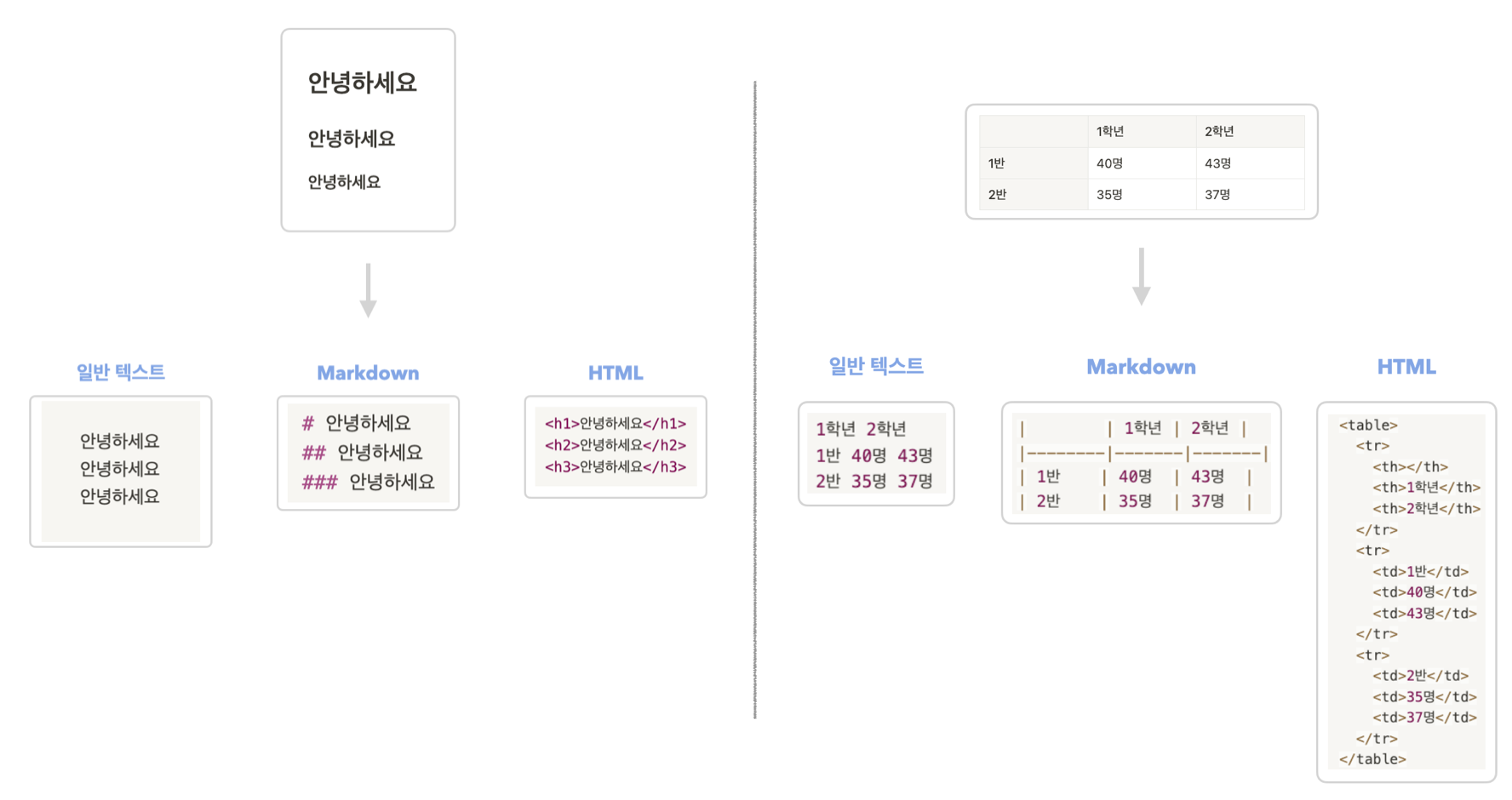
위처럼 마크업 언어들은 글의 크기와 단락, 표의 형태 등을 태그를 활용해 나타냄을 알 수 있어요.
마크업 언어가 RAG에 왜 좋을까요?
LLM이 똑똑한 이유는, 굉장히 많은 데이터로 학습되었기 때문이란 걸 잘 아실 거예요. 여기서 대부분의 데이터들은 웹상에서 수집이 되었을 텐데, 이들은 Markdown과 HTML과 같이 마크업 언어로 이루어져 있어요. 때문에 LLM은 마크업으로 표현된 글의 구조와 형식들을 그 누구보다 잘 캐치해 낼 수 있죠. 그러한 능력을 RAG에서 최대한 활용해야 하는 거죠. PDF 속의 내용을 단순히 텍스트로 표현했을 때는 그 글의 구조가 깨지지만, 마크업 언어로 표현한다면 이 구조를 그대로 살려서 LLM에게 보여줄 수 있습니다.
2. 마크업 언어로부터, 메타데이터를 추출하자
RAG에서 메타데이터의 활용성
RAG 시스템에선 문서를 로드하면 이를 벡터로 임베딩하기 위해, 적절한 크기로 자르는 Cunking이라는 작업을 진행합니다.

이렇게 잘린 chunk들을 바로 벡터로 임베딩 해도 되지만, 각각의 chunk에 메타데이터(문서의 제목, 문서의 페이지, 대제목 등)를 추가해서 임베딩을 하곤 합니다. 이는 검색 시 더 유의미한 결과를 유도할 수 있죠. 이때, 메타데이터를 추출하는 과정에서 마크업 언어가 유용하게 활용될 수 있습니다.
대제목 추출
아래와 같은 문서를 마크업으로 추출하면, 글의 대제목을 추출할 수 있고 이를 메타데이터로 활용할 수 있습니다. 대제목은 이어지는 chunk들이 대략적으로 어떤 내용인지 알려줄 수 있는 좋은 정보기에, 이를 chunk에 추가해서 임베딩하면 검색시 유의미하게 활용될 수 있을 거라 생각해요. 현대자동차 설명서에는 각 기능 설명 위에는 항상 대제목이 존재했기에 메타데이터로서 활용이 좋다고 판단했습니다.
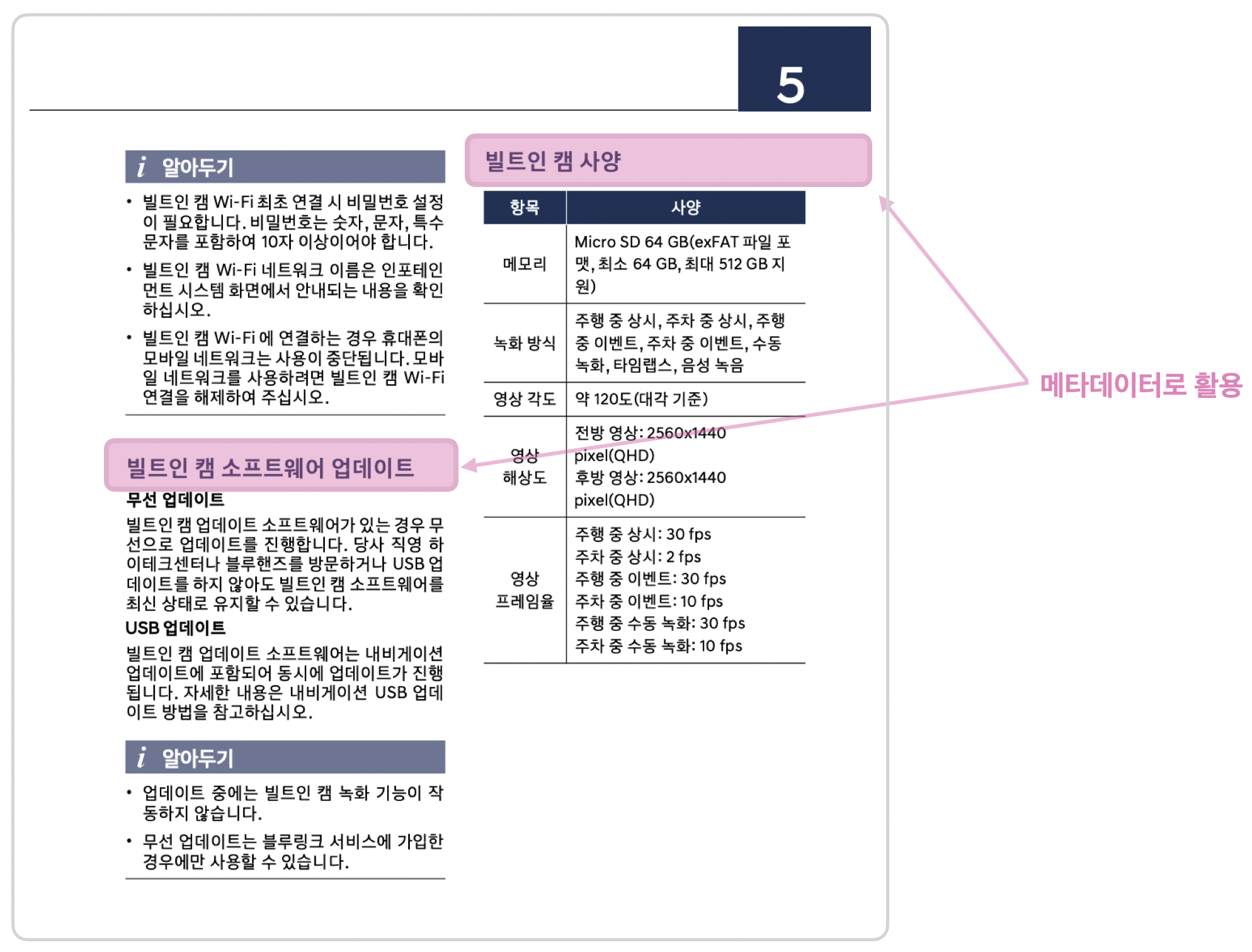
또한 Vector를 검색할 때, 필터로써도 활용될 수 있습니다.
만약 마크업이 아닌 일반 텍스트로 추출했다면, 이렇게 대제목을 추출하는 작업은 꽤나 까다로운 작업이었을 거예요.
Chunking 기준으로 활용
긴 글을 chunking 하는 방법은 매우 다양해요. 가장 기본적으로, 정해진 토큰 수만큼 잘라내는 방법이 있죠. 하지만, 이 방법은 하나의 chunk에 서로 관련이 없는 내용들이 포함될 수 있어요. 만약 pdf를 마크업 언어로, 글의 구조를 잘 추출할 수 있다면 대제목 혹은 중제목을 기준으로 chunking을 할 수 있는 선택권이 생깁니다. 이는 내용의 카테고리별로 chunking을 하는 셈이 됩니다. 현대자동차 설명서 같은 경우, 각 기능별로 카테고리가 확실히 분리되어 있기 때문에 아래와 같이 특정 카테고리 별로 chunking을 시도해 볼 수 있었죠.

3. PDF를 마크업 언어로 추출해 주는 다양한 툴
PDF를 마크업 언어로 추출해 주는 도구는 매우 많습니다. 저는 다양한 툴들 중 아래 2가지를 비교해 봤습니다.
Markdown 추출 : PymuPDF4LLM
PymuPDF4LLM은 PDF를 Markdown 형식으로 추출해 주는 도구입니다.
해당 도구는 전반적으로 단순 PDF 로더에 비해, 텍스트 추출 정확도는 좋았지만 예상치 못한 곳에서 Markdown 태그 정확도가 좋지 않았습니다. 특히 한 가지 아쉬웠던 점은 글의 구조가 2열로 이루어진 경우 글이 추출되는 순서가 제각각이었다는 점 입니다. 보통 2열로 구성된 PDF는 1열을 다 읽은 후 2열로 넘어가지만, PymuPDF에선 지그재그 형식으로 글을 읽어 들이는 경우가 종종 있었습니다. 이는 chunking 시 악영향을 끼칠수도 있겠단 생각이 들었습니다.

HTML 추출 : Upstage Layout Analysis
Upstage Layout Analysis는 PDF를 HTML 형식으로 추출해 주는 도구입니다. 해당 도구는 폰트의 사이즈, 링크 등등 Markdown보다 더 자세한 정보를 제공해 주었고, 다른 도구들 보다 정확도 측면에서 강점을 가졌습니다. 2열 구조의 PDF도 잘 읽어냈었죠.

한가지 아쉬웠던 점은, Markdown 출력은 지원해 주지 않는다는 점입니다. 현재(2024년 11월 13일), Upstage의 LayoutAnalysis는 Document Parser로 업그레이드 되었으며, Markdown도 함께 출력해 줍니다! HTML은 Markdown에 비해 더욱더 자세한 구조적 정보를 줄 순 있지만, 그만큼 텍스트와 토큰의 길이가 길어집니다. 이는 자연스럽게 LLM의 비용을 증가시키기도 하죠.
[동일한 문서를 기준으로,]
- Markdown -> 1,470
- HTML -> 1794
현대자동차 설명서 같은 경우, 글의 구조가 Markdown으로도 충분히 커버가 될 만한 복잡도를 가졌기에 더욱더 아쉬움이 남았습니다. 하지만, 토큰의 길이보다는 정확도가 우선이라 판단하여 최종적으론 Upstage의 Layout Analysis 도구를 활용하여 PDF를 로드하였습니다.
RAG 시스템의 성능을 어떻게 평가하지?
AI 모델을 학습시키거나 적용해 보신 분은 잘 아실 테지만, 문서를 로드하는 방법에는 정해진 정답이 없는 것 같습니다.
어떤 도메인인지, PDF 문서 구조가 어떤지 등에 따라 최적의 추출방법은 달라질 테죠.
단지 LLM관점에서 어떤 게 더 좋을 것이다라는 가설을 가지고 실험을 해보는 수밖에 없다고 생각합니다.
현대 자동차 챗봇 프로젝트를 지금까지 개인적으로 진행해 보면서 한 가지 궁금증이 생겼습니다.
“다양한 문서 추출 방법, 다양한 검색 방법들을 적용해 볼 텐데, 어떤 게 좋은 방법이지?”
즉, RAG시스템의 성능을 어떻게 평가하지?라는 질문이 자연스럽게 생기더군요.
다음 포스팅에서는 해당 질문에 대한 해답을 가지고 찾아뵙도록 하겠습니다.
'Tech > 현대자동차 설명서 챗봇' 카테고리의 다른 글
| RAG | 현대자동차 챗봇 구현기 - 성능 최적화(feat. 평가데이터 전처리 툴) (4) | 2024.11.10 |
|---|---|
| RAG | 현대자동차 챗봇 구현기 (4) | 2024.05.26 |
PDF를 잘 읽는 게 중요한 이유
RAG(Recurrent Attention-Gated) 시스템을 구성하기 위해 가장 먼저 해야 할 작업은 문서를 텍스트 형태로 로드하는 작업이에요. 만약 문서의 종류가 Excel이나 Code 파일 같이 정형화된 파일일 경우, 텍스트로 변환하는 과정이 비교적 수월할 수 있습니다. 하지만, PDF 같이 비정형 파일들은 텍스트로 변환할 때 여러 가지 고려사항이 필요합니다. 아래는 PDF 파일을 단순히 텍스트로 변환한 예시예요.
위의 결과를 보면 PDF 내의 텍스트는 잘 불러온 것처럼 보이지만, 글의 단락과 구성이 반영되어 있지 않고 표의 정보도 깨져 있음을 볼 수 있어요. 사람에게 우측과 같이 텍스트만 제공하면, 정보를 제대로 파악하지 못할 가능성이 큽니다. 이는 LLM(Large Language Model)도 마찬가지예요. 이러한 변환 오류는 RAG의 성능에 부정적인 영향을 미칠 수 있습니다.
현대자동차 챗봇을 구현해 보며 PDF를 로드하는 과정에서 제가 시도했던 방법들과 그 결과물들을 공유하려고 합니다.
1. PDF를 마크업 언어로 추출하자
마크업 언어란?
마크업 언어란, 문서의 형식이나 구조를 명시하기 위한 규칙을 가진 언어입니다. 대표적으로 Markdown과 HTML이 있죠. 아래의 예시를 보면 마크업 언어를 쉽게 이해할 수 있을 거예요.
위처럼 마크업 언어들은 글의 크기와 단락, 표의 형태 등을 태그를 활용해 나타냄을 알 수 있어요.
마크업 언어가 RAG에 왜 좋을까요?
LLM이 똑똑한 이유는, 굉장히 많은 데이터로 학습되었기 때문이란 걸 잘 아실 거예요. 여기서 대부분의 데이터들은 웹상에서 수집이 되었을 텐데, 이들은 Markdown과 HTML과 같이 마크업 언어로 이루어져 있어요. 때문에 LLM은 마크업으로 표현된 글의 구조와 형식들을 그 누구보다 잘 캐치해 낼 수 있죠. 그러한 능력을 RAG에서 최대한 활용해야 하는 거죠. PDF 속의 내용을 단순히 텍스트로 표현했을 때는 그 글의 구조가 깨지지만, 마크업 언어로 표현한다면 이 구조를 그대로 살려서 LLM에게 보여줄 수 있습니다.
2. 마크업 언어로부터, 메타데이터를 추출하자
RAG에서 메타데이터의 활용성
RAG 시스템에선 문서를 로드하면 이를 벡터로 임베딩하기 위해, 적절한 크기로 자르는 Cunking이라는 작업을 진행합니다.
이렇게 잘린 chunk들을 바로 벡터로 임베딩 해도 되지만, 각각의 chunk에 메타데이터(문서의 제목, 문서의 페이지, 대제목 등)를 추가해서 임베딩을 하곤 합니다. 이는 검색 시 더 유의미한 결과를 유도할 수 있죠. 이때, 메타데이터를 추출하는 과정에서 마크업 언어가 유용하게 활용될 수 있습니다.
대제목 추출
아래와 같은 문서를 마크업으로 추출하면, 글의 대제목을 추출할 수 있고 이를 메타데이터로 활용할 수 있습니다. 대제목은 이어지는 chunk들이 대략적으로 어떤 내용인지 알려줄 수 있는 좋은 정보기에, 이를 chunk에 추가해서 임베딩하면 검색시 유의미하게 활용될 수 있을 거라 생각해요. 현대자동차 설명서에는 각 기능 설명 위에는 항상 대제목이 존재했기에 메타데이터로서 활용이 좋다고 판단했습니다.
또한 Vector를 검색할 때, 필터로써도 활용될 수 있습니다.
만약 마크업이 아닌 일반 텍스트로 추출했다면, 이렇게 대제목을 추출하는 작업은 꽤나 까다로운 작업이었을 거예요.
Chunking 기준으로 활용
긴 글을 chunking 하는 방법은 매우 다양해요. 가장 기본적으로, 정해진 토큰 수만큼 잘라내는 방법이 있죠. 하지만, 이 방법은 하나의 chunk에 서로 관련이 없는 내용들이 포함될 수 있어요. 만약 pdf를 마크업 언어로, 글의 구조를 잘 추출할 수 있다면 대제목 혹은 중제목을 기준으로 chunking을 할 수 있는 선택권이 생깁니다. 이는 내용의 카테고리별로 chunking을 하는 셈이 됩니다. 현대자동차 설명서 같은 경우, 각 기능별로 카테고리가 확실히 분리되어 있기 때문에 아래와 같이 특정 카테고리 별로 chunking을 시도해 볼 수 있었죠.
3. PDF를 마크업 언어로 추출해 주는 다양한 툴
PDF를 마크업 언어로 추출해 주는 도구는 매우 많습니다. 저는 다양한 툴들 중 아래 2가지를 비교해 봤습니다.
Markdown 추출 : PymuPDF4LLM
PymuPDF4LLM은 PDF를 Markdown 형식으로 추출해 주는 도구입니다.
해당 도구는 전반적으로 단순 PDF 로더에 비해, 텍스트 추출 정확도는 좋았지만 예상치 못한 곳에서 Markdown 태그 정확도가 좋지 않았습니다. 특히 한 가지 아쉬웠던 점은 글의 구조가 2열로 이루어진 경우 글이 추출되는 순서가 제각각이었다는 점 입니다. 보통 2열로 구성된 PDF는 1열을 다 읽은 후 2열로 넘어가지만, PymuPDF에선 지그재그 형식으로 글을 읽어 들이는 경우가 종종 있었습니다. 이는 chunking 시 악영향을 끼칠수도 있겠단 생각이 들었습니다.
HTML 추출 : Upstage Layout Analysis
Upstage Layout Analysis는 PDF를 HTML 형식으로 추출해 주는 도구입니다. 해당 도구는 폰트의 사이즈, 링크 등등 Markdown보다 더 자세한 정보를 제공해 주었고, 다른 도구들 보다 정확도 측면에서 강점을 가졌습니다. 2열 구조의 PDF도 잘 읽어냈었죠.
한가지 아쉬웠던 점은, Markdown 출력은 지원해 주지 않는다는 점입니다. 현재(2024년 11월 13일), Upstage의 LayoutAnalysis는 Document Parser로 업그레이드 되었으며, Markdown도 함께 출력해 줍니다! HTML은 Markdown에 비해 더욱더 자세한 구조적 정보를 줄 순 있지만, 그만큼 텍스트와 토큰의 길이가 길어집니다. 이는 자연스럽게 LLM의 비용을 증가시키기도 하죠.
[동일한 문서를 기준으로,]
- Markdown -> 1,470
- HTML -> 1794
현대자동차 설명서 같은 경우, 글의 구조가 Markdown으로도 충분히 커버가 될 만한 복잡도를 가졌기에 더욱더 아쉬움이 남았습니다. 하지만, 토큰의 길이보다는 정확도가 우선이라 판단하여 최종적으론 Upstage의 Layout Analysis 도구를 활용하여 PDF를 로드하였습니다.
RAG 시스템의 성능을 어떻게 평가하지?
AI 모델을 학습시키거나 적용해 보신 분은 잘 아실 테지만, 문서를 로드하는 방법에는 정해진 정답이 없는 것 같습니다.
어떤 도메인인지, PDF 문서 구조가 어떤지 등에 따라 최적의 추출방법은 달라질 테죠.
단지 LLM관점에서 어떤 게 더 좋을 것이다라는 가설을 가지고 실험을 해보는 수밖에 없다고 생각합니다.
현대 자동차 챗봇 프로젝트를 지금까지 개인적으로 진행해 보면서 한 가지 궁금증이 생겼습니다.
“다양한 문서 추출 방법, 다양한 검색 방법들을 적용해 볼 텐데, 어떤 게 좋은 방법이지?”
즉, RAG시스템의 성능을 어떻게 평가하지?라는 질문이 자연스럽게 생기더군요.
다음 포스팅에서는 해당 질문에 대한 해답을 가지고 찾아뵙도록 하겠습니다.
'Tech > 현대자동차 설명서 챗봇' 카테고리의 다른 글
| RAG | 현대자동차 챗봇 구현기 - 성능 최적화(feat. 평가데이터 전처리 툴) (4) | 2024.11.10 |
|---|---|
| RAG | 현대자동차 챗봇 구현기 (4) | 2024.05.26 |